EfficientNet V1
-
EfficientNet主要是用NAS(Neural Architecture Search)技术来搜索网络的图像输入分辨率 r ,网络的深度depth以及channel的宽度width三个参数的合理化配置,之前的论文都是都是通过改变上述3个参数中的一个来提升网络的性能,参数少,推理速度块,但比较占显存
- 增加网络的深度depth能够得到更加丰富、复杂的特征,但网络的深度过深会面临梯度消失的问题
- 增加网络的width能够获得更高细粒度的特征,但对于width很大而深度较浅的网络往往很难学习到更深层次的特征
- 增加输入网络的图像分辨率能够获得更高细粒度的特征模板,但对于非常高的输入分辨率,准确率的增益也会减小,并且大分辨率图像会增加计算量
-
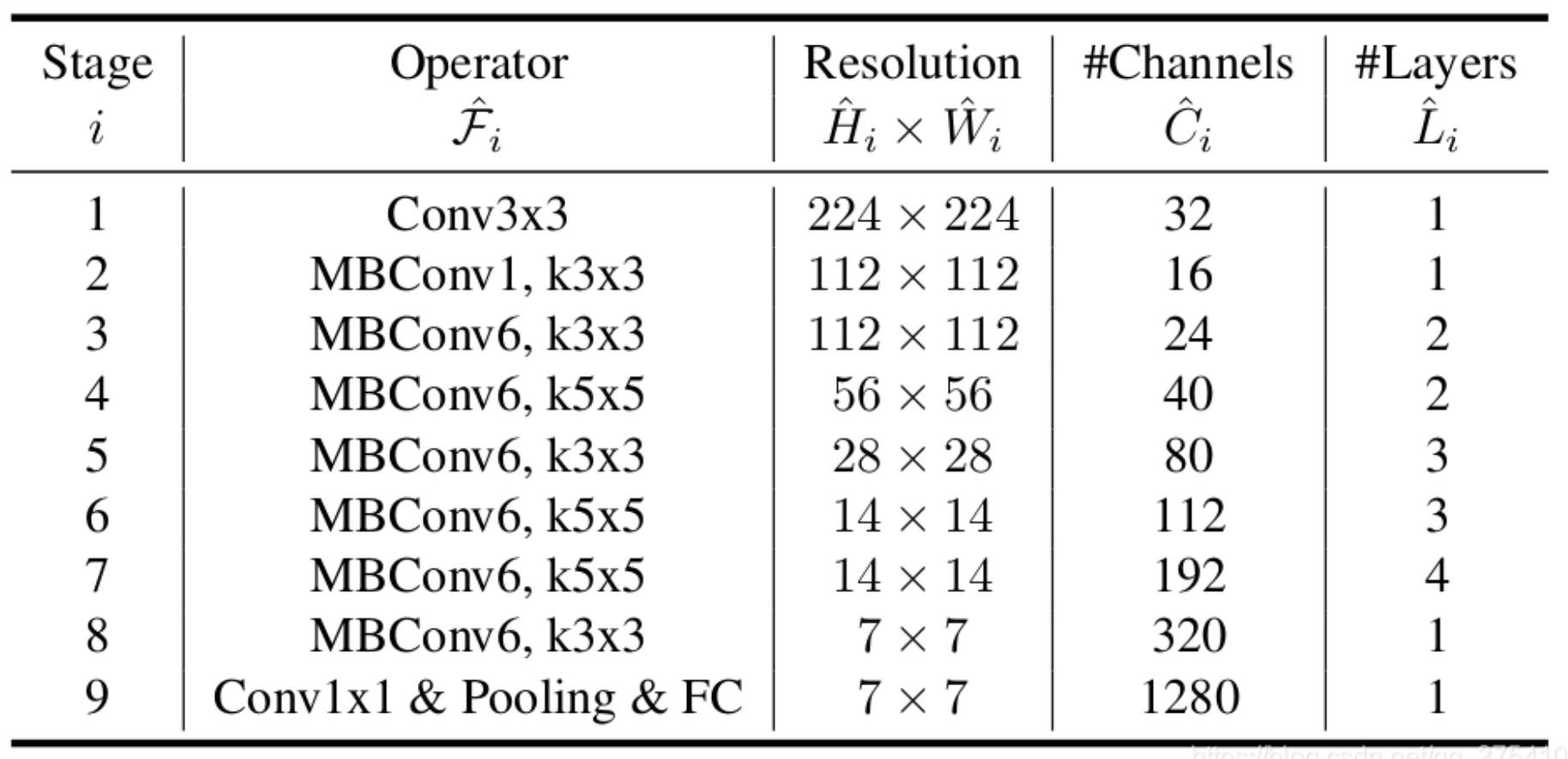
网络详细结构:下表为EfficientNet-B0的网络框架(B1-B7就是在B0的基础上修改Resolution,Channels以及Layers),可以看出网络总共分成了9个Stage,第一个Stage就是一个卷积核大小为3x3步距为2的普通卷积层(包含BN和激活函数Swish),Stage2~Stage8都是在重复堆叠MBConv结构(最后一列的Layers表示该Stage重复MBConv结构多少次),而Stage9由一个普通的1x1的卷积层(包含BN和激活函数Swish)一个平均池化层和一个全连接层组成。表格中每个MBConv后会跟一个数字1或6,这里的1或6就是倍率因子n,即MBConv中第一个1x1的卷积层会将输入特征矩阵的channels扩充为n倍,其中k3x3或k5x5表示MBConv中Depthwise Conv所采用的卷积核大小。Channels表示通过该Stage后输出特征矩阵的Channels
-
MBConv结构
-
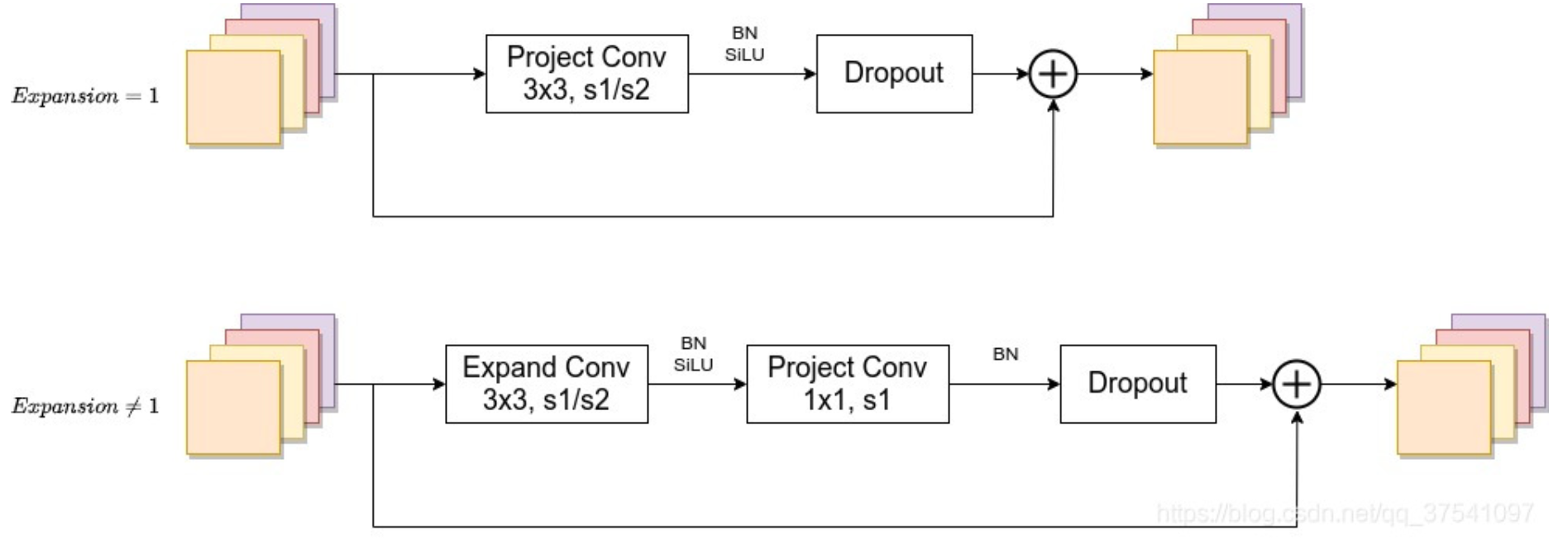
第一个卷积层用于升维,stage2中没有升维卷积层,因为倍率因子=1
-
关于shortcut连接,仅当stride=1并且输入MBConv结构的特征矩阵与输出的特征矩阵shape相同时才存在(代码中可通过
stride==1 and inputc_channels==output_channels条件来判断) -
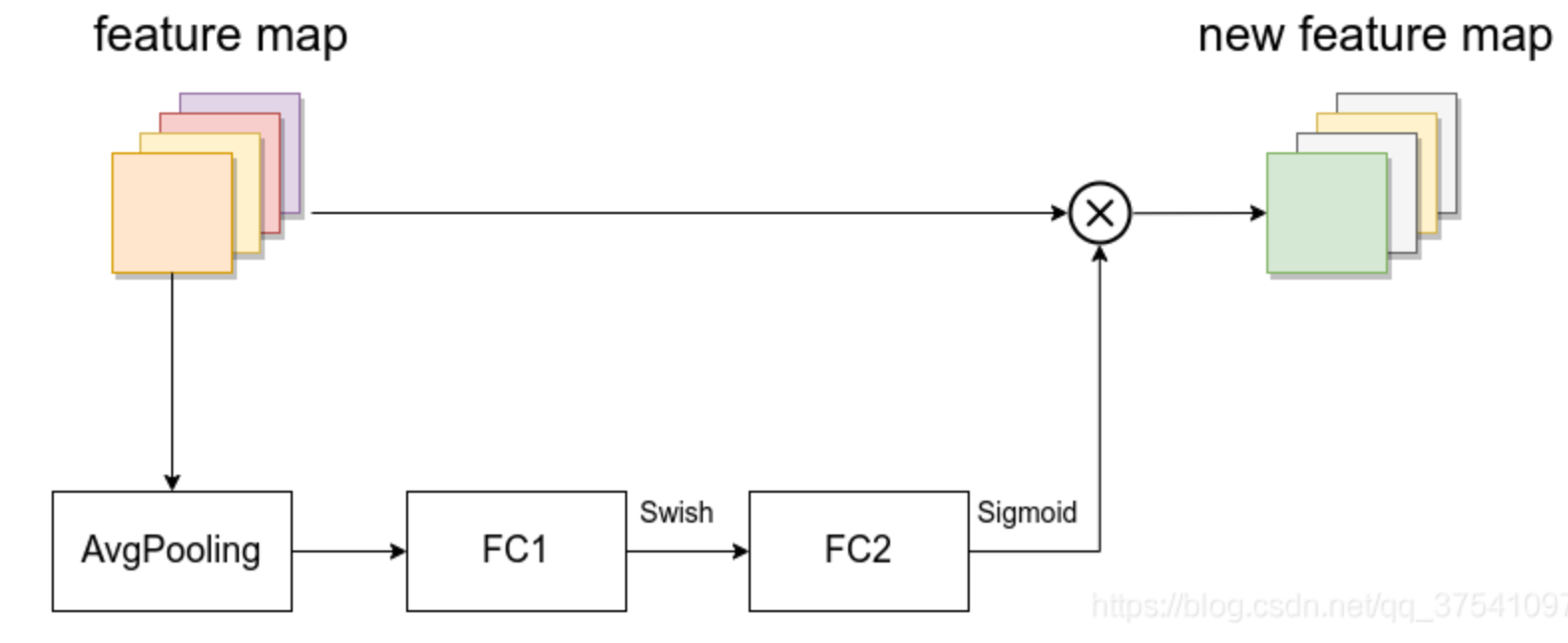
SE模块是注意力机制,由一个全局平均池化,两个全连接层组成

-
-
MBConv中Dropout层的结构
-
EfficientNet V2
-
EfficientNet V1中作者关注的是准确率,参数数量以及FLOPs(注意理论计算量小不代表推理速度快),在EfficientNet V2中作者进一步关注模型的训练速度
-
EfficientNet V1中存在的问题:
- 训练图像的尺寸很大时,训练速度非常慢
- 在网络浅层中使用Depthwise convolutions速度会很慢
- 同等的放大每个stage是次优的
-
EfficientNet V2的三个贡献:
- 该网络在训练速度以及参数数量上都优于先前的一些网络
- 提出了改进的渐进学习方法,该方法会根据训练图像的尺寸动态调节正则方法(例如dropout、data augmentation和mixup),通过实验展示了该方法不仅能够提升训练速度,同时还能提升准确率
- 与先前的一些网络相比,训练速度提升11倍,参数数量减少为$\frac{1}{6.8}$
-
EfficientNetV2网络框架:
-
在网络浅层中使用使用了Fused-MBConv模块,即将expansion conv1x1和depthwise conv3x3替换成一个普通的conv3x3
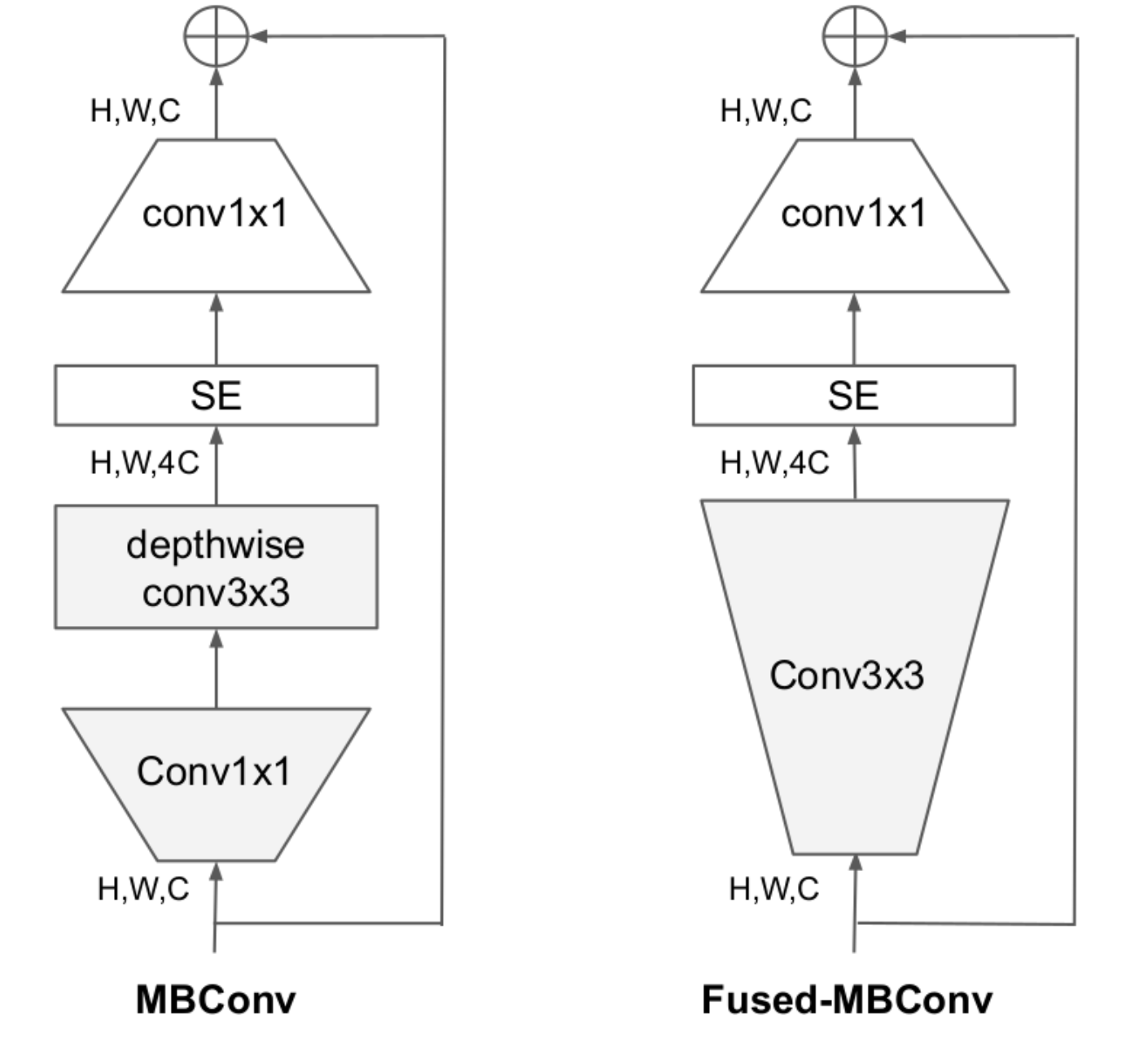
当有shortcut连接时才有Dropout层,而且这里的Dropout层是Stochastic Depth,即会随机丢掉整个block的主分支;源代码中没有使用到SE结构的,而原论文图中有SE
-
EfficientNetV2会使用较小的expansion ratio,以减少内存访问开销
-
EfficientNetV2更偏向使用更小(3x3)的kernel_size
-
移除了EfficientNetV1中最后一个步距为1的stage
-
-
Progressive Learning 渐进学习策略
在之前的一些工作中很多人尝试使用动态的图像尺寸(比如一开始用很小的图像尺寸,后面再增大)来加速网络的训练,但通常会导致Accuracy降低,作者提出了一个猜想:Accuracy的降低是不平衡的正则化(unbalanced regularization)导致的,在训练不同尺寸的图像时,应该使用动态的正则方法
即:在训练早期使用较小的训练尺寸以及较弱的正则方法,这样网络能够快速的学习到一些简单的表达能力。接着逐渐提升图像尺寸,同时增强正则方法,防止过拟合
本着互联网开源的性质,欢迎分享这篇文章,以帮助到更多的人,谢谢!