Transformer概述
-
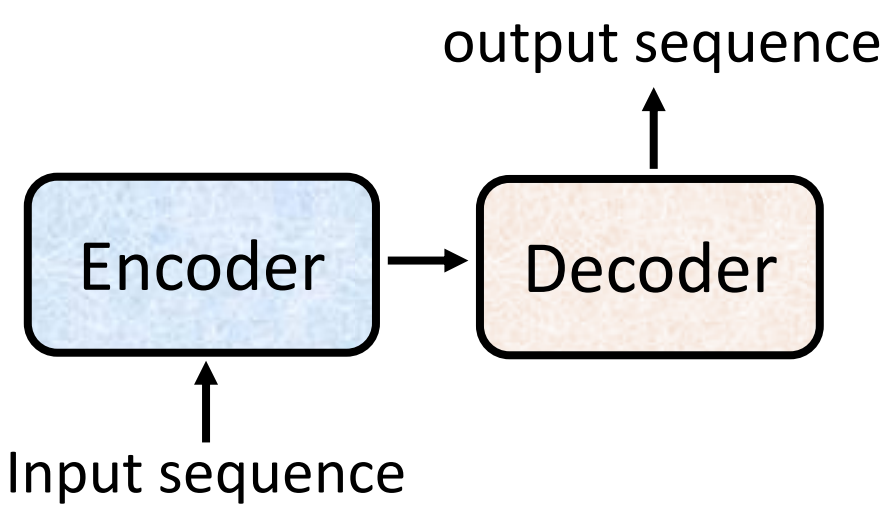
核心是seq2seq模型,能处理很多的问题;一般的seq2seq模型分成两个部分:encoder和decoder,encoder负责处理input sequence,把处理结果给decoder,由decoder决定输出什么样的sequence
-
encoder是Transformer的核心,将特征更好地提取出来,decoder在具体的任务中使用
-
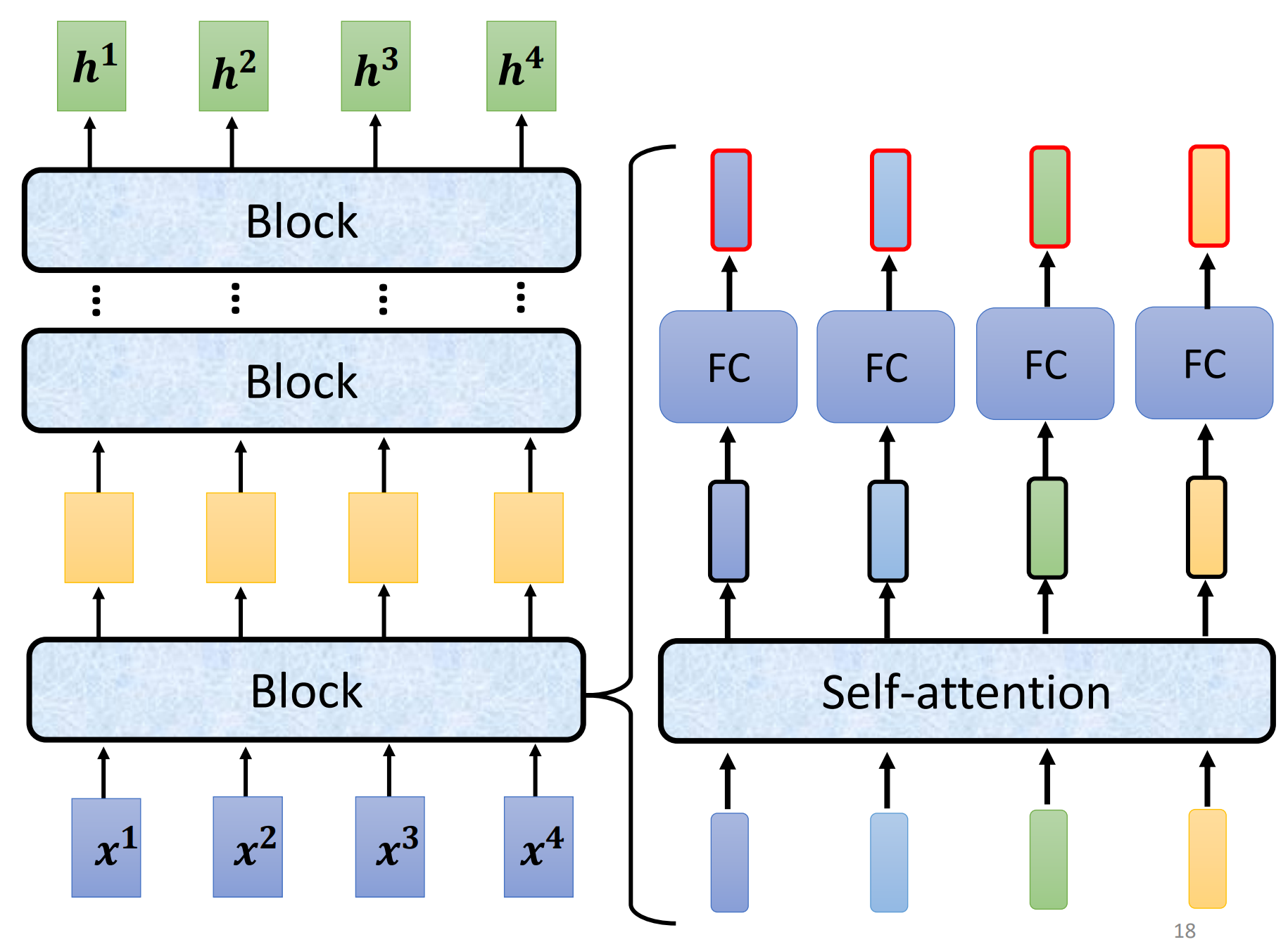
encoder:给一排向量,输出一排向量,transformer用的encoder是self-attention;
每一个encoder会分成很多个block,每一个block由很多层组成
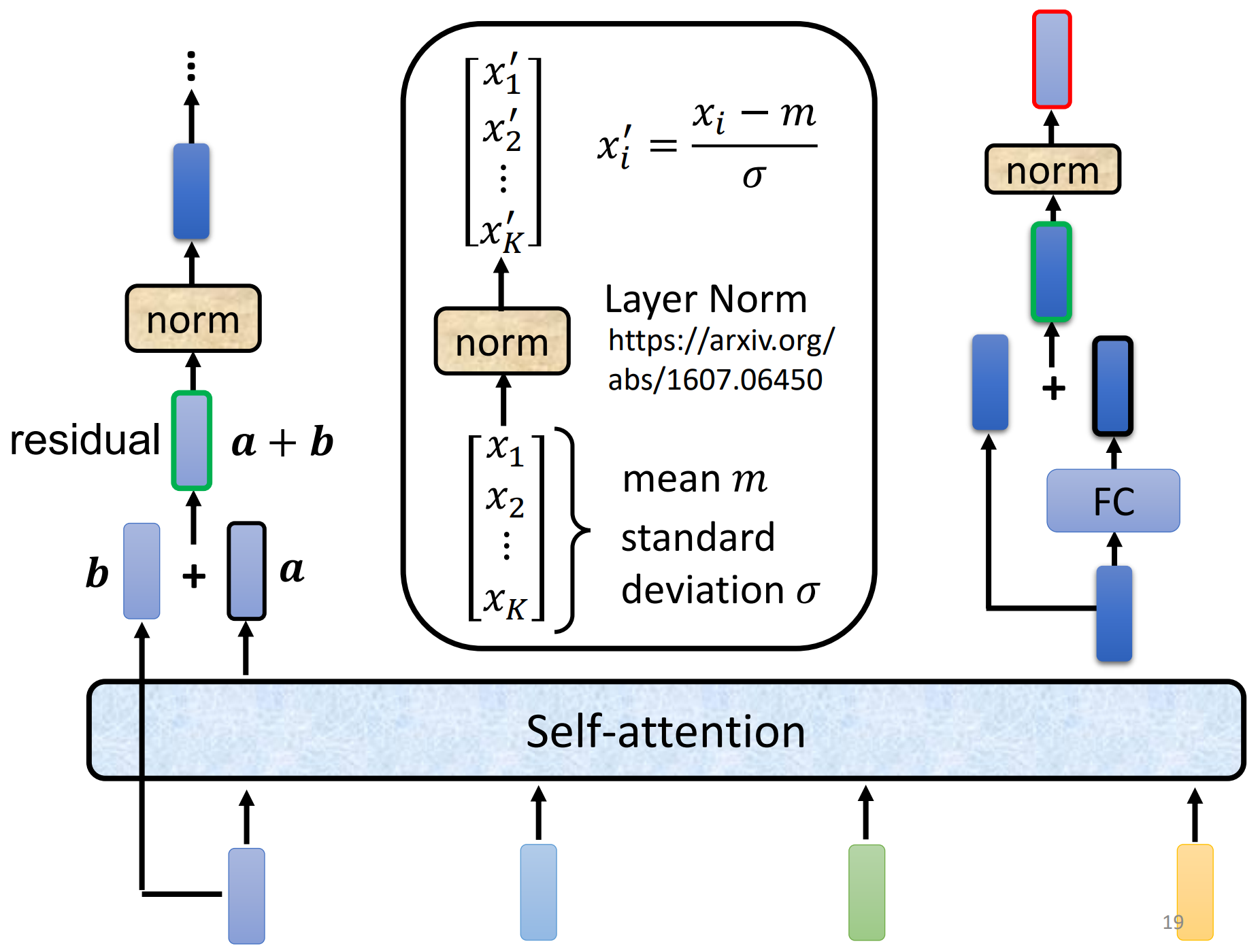
在真正的transformer中更加复杂,在加入positional encoding后,首先加入了残差连接(residual connection),再将输出结果做layer normalization,得到的输出才是全连接层的输入,再做一次residual和normalizaton得到最终block的输出
(注:batch normalization是对一批样本的同一纬度特征做归一化;layer normalization是对单个样本的所有维度特征做归一化)
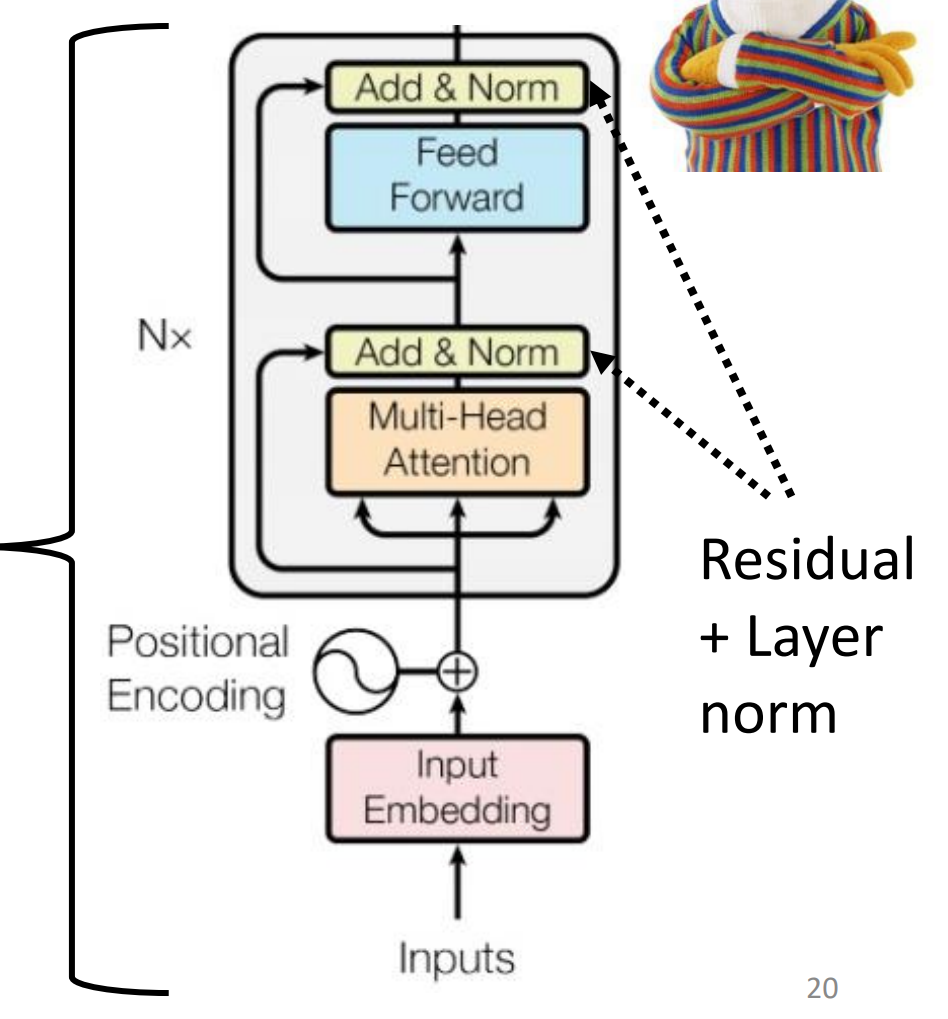
最终的模型图:
-
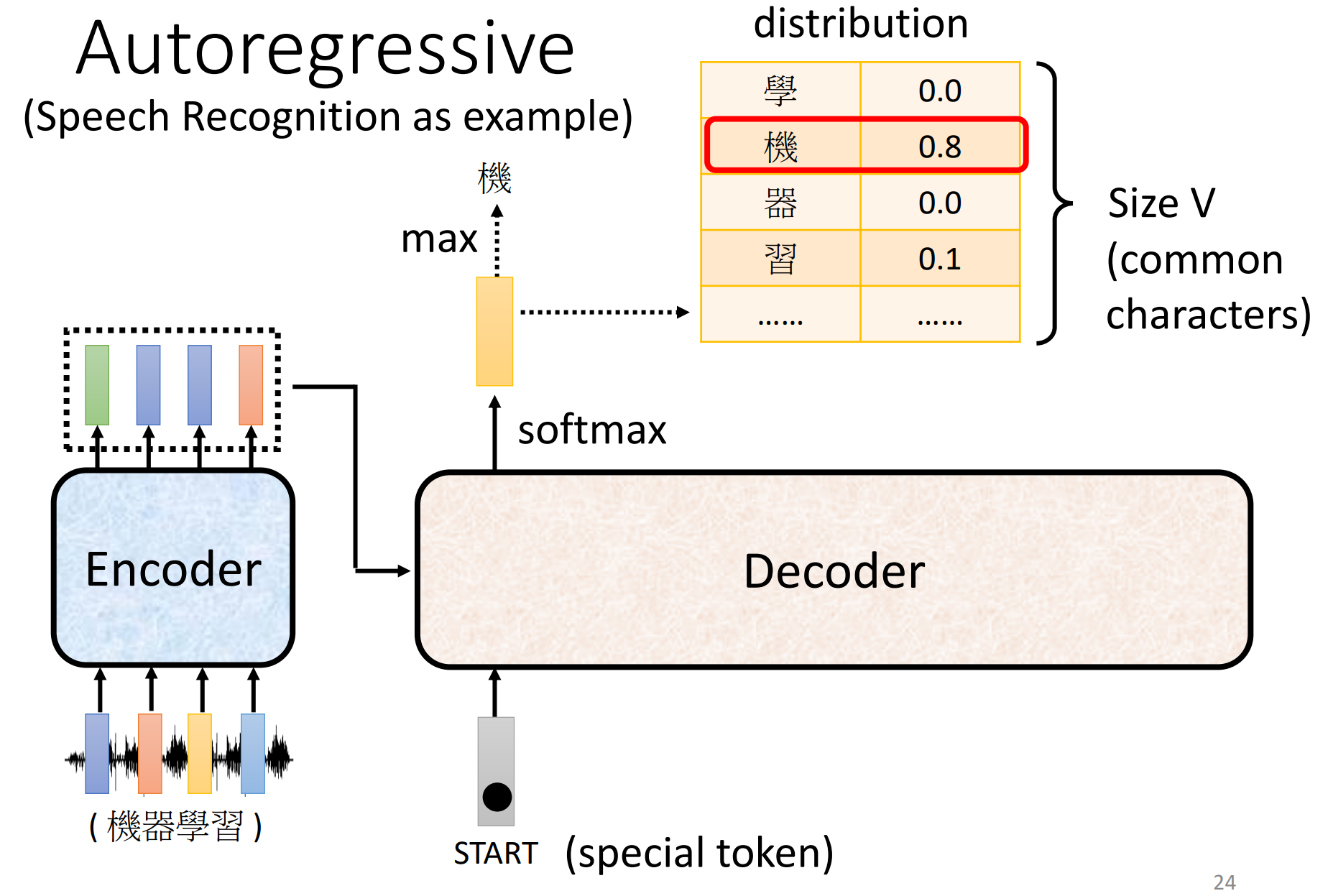
decoder:介绍decoder中最常见的一种decoder——Autoregressive decoder
首先给decoder输入一个表示begin of sentence的特殊向量START,根据encoder给出的的输入向量输出第一个向量,做一个softmax,得到每一个汉字的概率(长度是汉字的数量),取最大值作为输出
将第一个输出的向量作为第二个输出向量的输入向量,重复上面的步骤,依次得到最终的结果
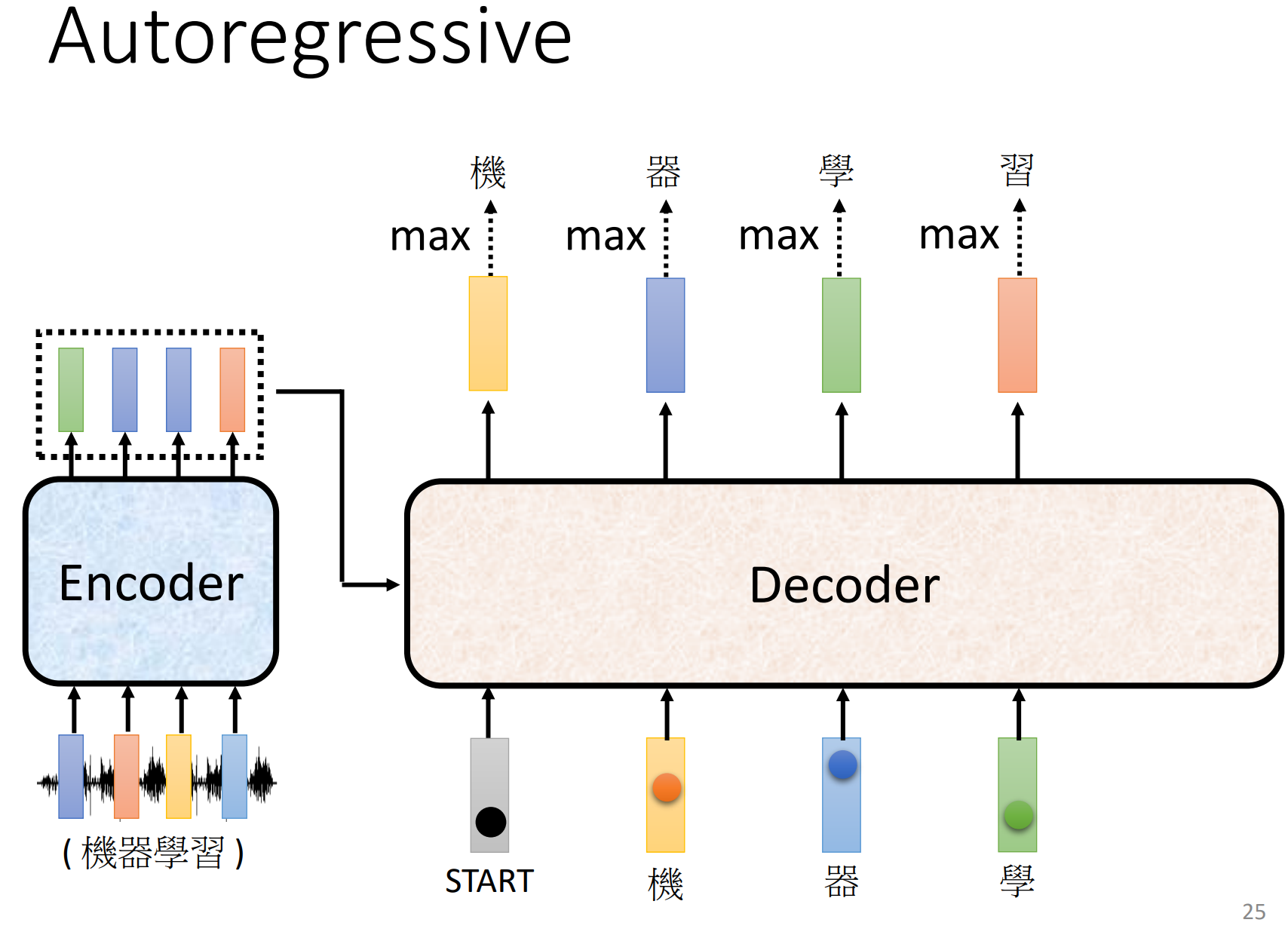
-
内部结构:
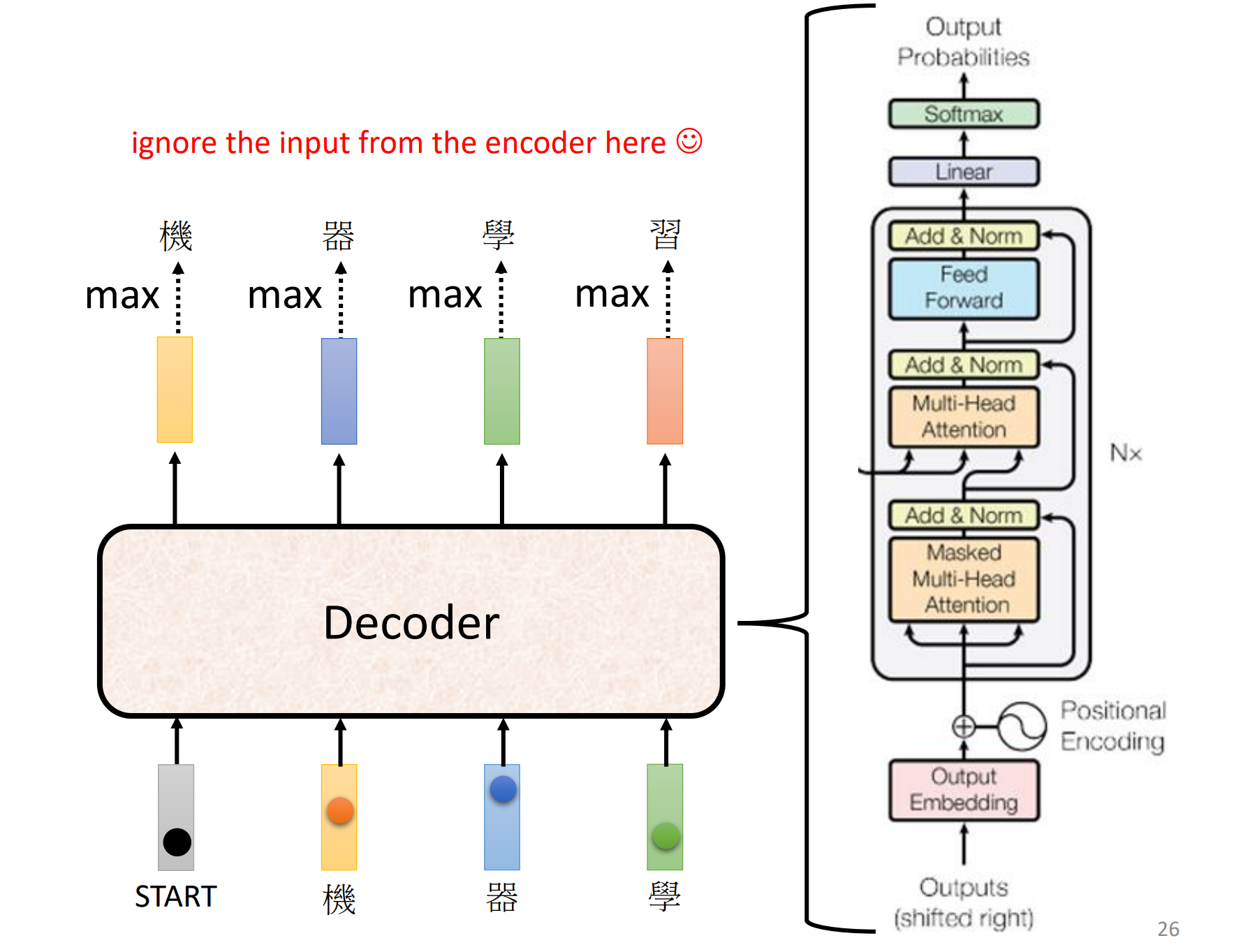
去掉中间这一块和encoder几乎一样
-
Masked:在做self-attention时,只关注序列中当前元素左边的元素,因为右边的元素还未产生(encoder是并行,decoder是串行)
-
-
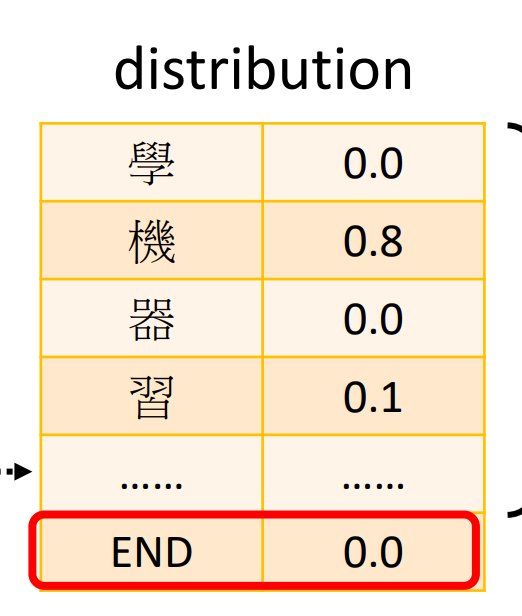
decoder如何决定输出sequence的长度:当输出END时,表示这个sequence要停止了
-
NAT(Non-autoregressive):
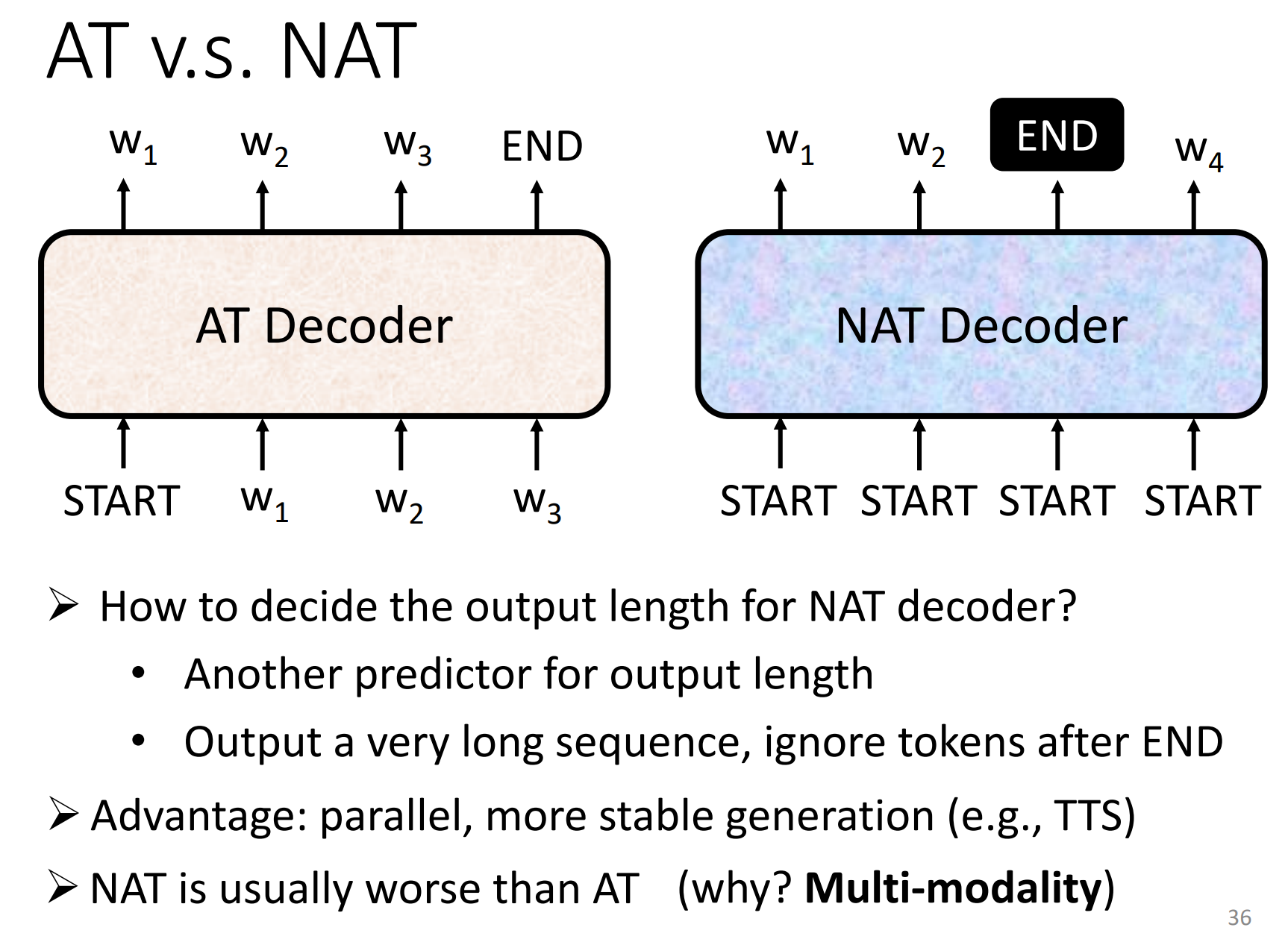
-
-
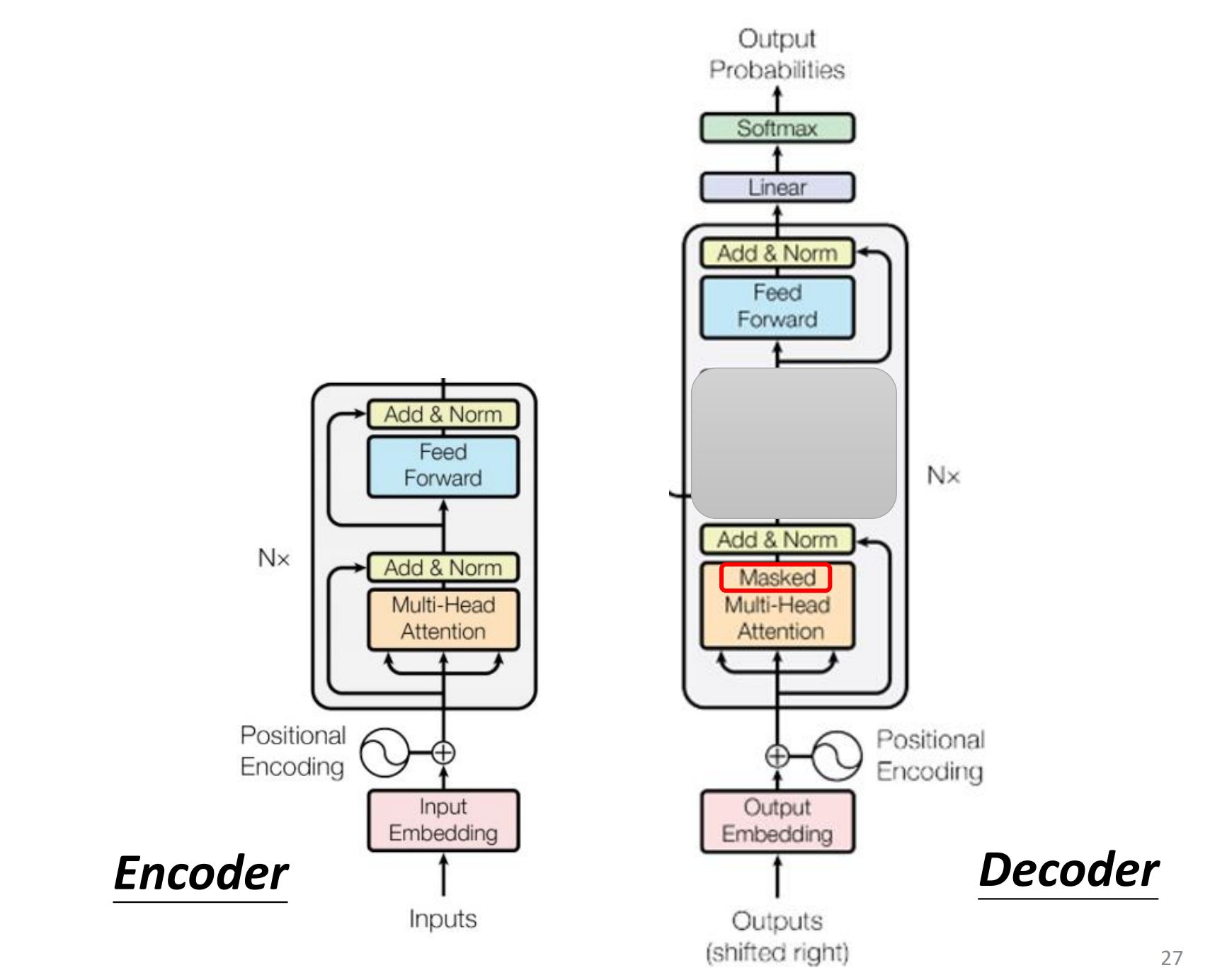
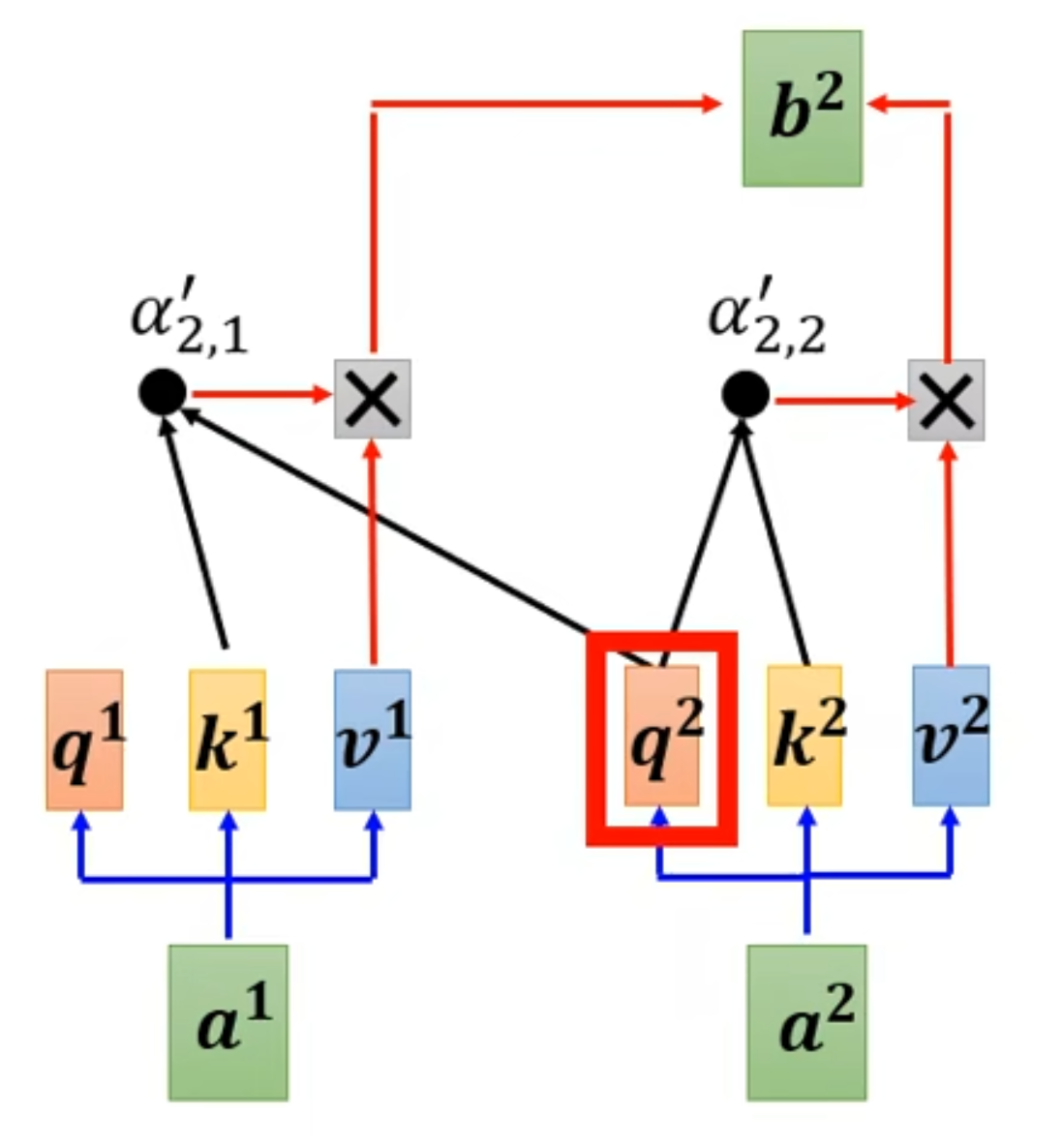
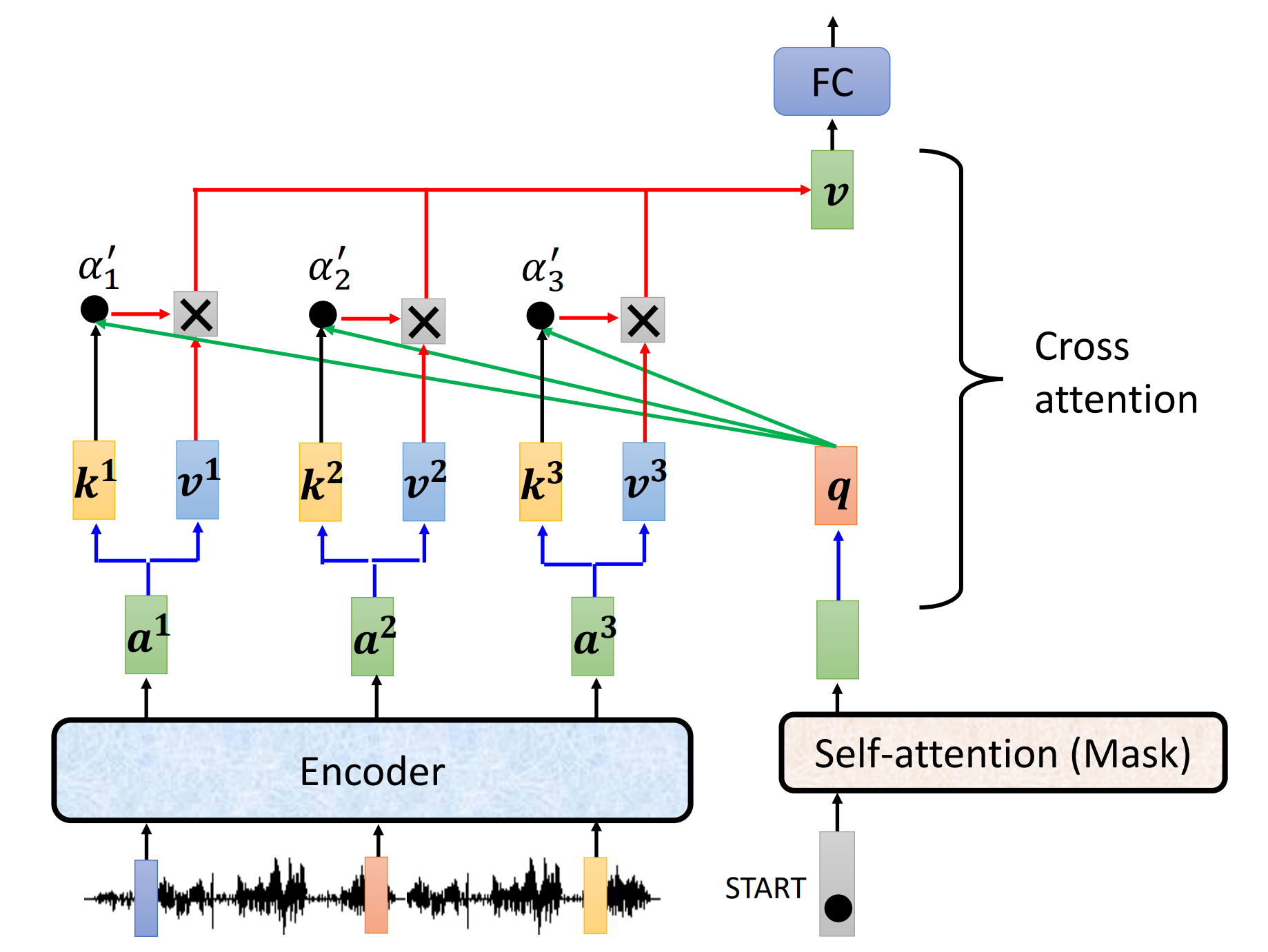
encoder和decoder是怎么连接的,上面被遮住的就是连接处,即Cross attention
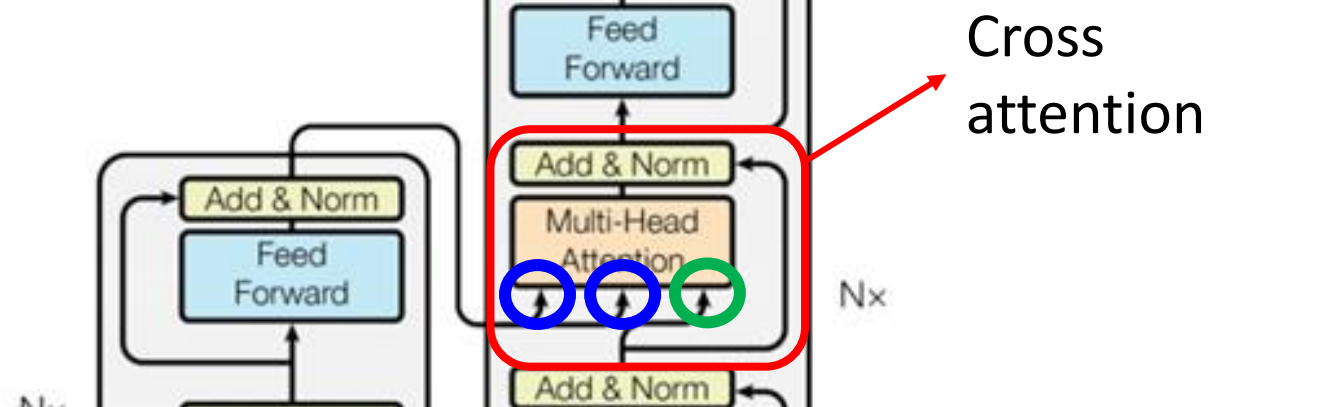
由decoder的attention产生$q$,由encoder的attention产生$k$和$v$,然后交叉做attention
-
Training:在decoder训练的时候,输入的是正确答案,计算交叉熵损失函数,是交叉熵最小(Teacher Forcing)
tips:
-
Copy Mechanism

-
本着互联网开源的性质,欢迎分享这篇文章,以帮助到更多的人,谢谢!