Vision Transformer
-
整体架构:
- 构建patch:将一张图片分成了9个小块,即9个patch,再把每一个patch都 ”拉长“ (一次卷积计算)成一个向量,这样就转换成了一个vector set,然后通过一个全连接层,做一个特征整合和维度变换
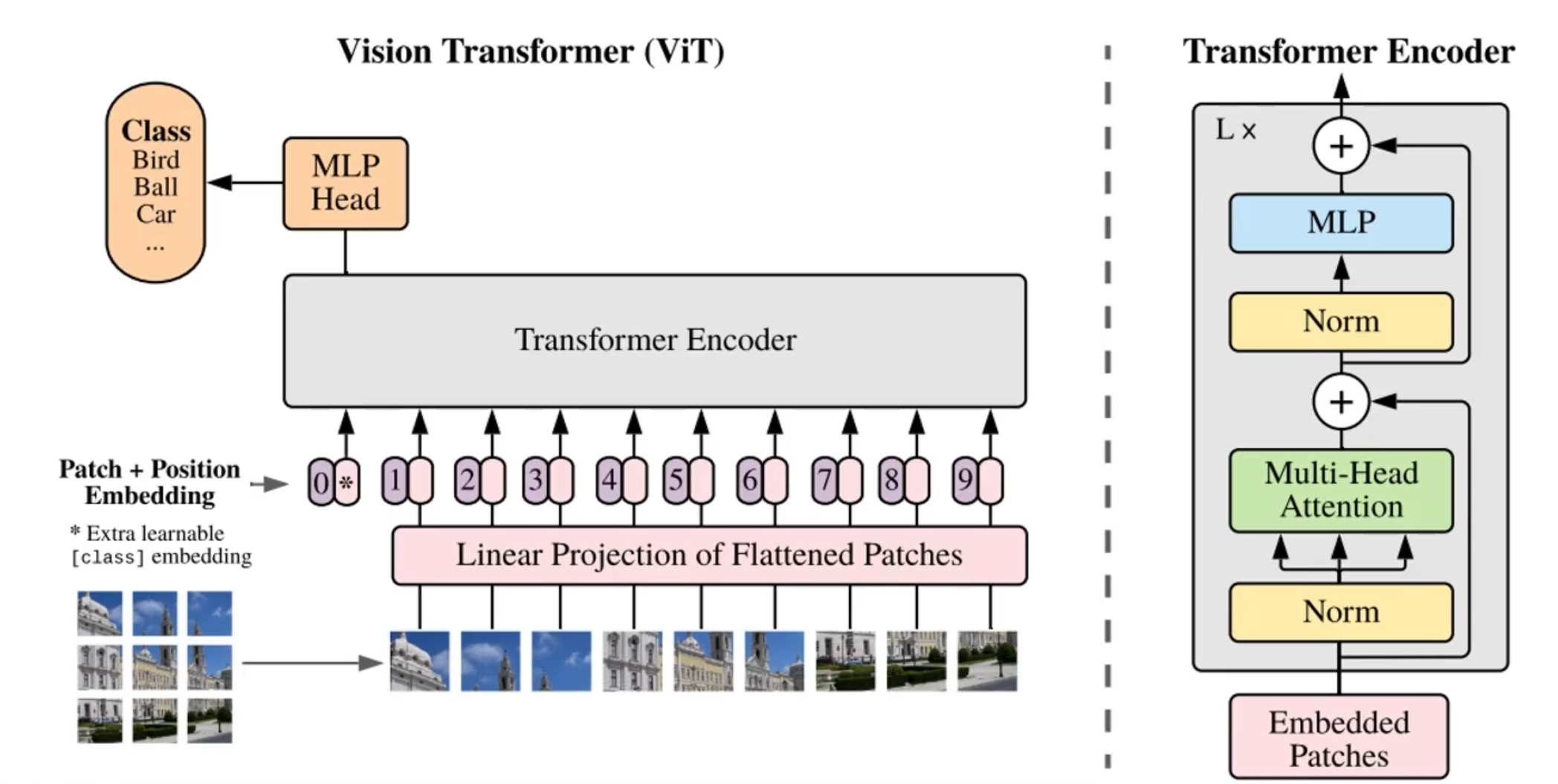
-
位置编码:在图像中,位置编码尤为重要,两种方法,一种是在每一个vector前面加上一个位置ID,另一种方法是加上一个空间坐标,这样更符合空间分布
-
用于分类的token:当模型用于分类时,额外加了一个token,标号为0,在每次的attention计算中,这个token都整合了全局的信息,最后分类时将这个token输出的向量拿去做分类即可
Transformer in Transformer
-
分为外部Transformer和内部Transformer,外部Transformer和ViT基本相同,再细分可以分出来内部Transformer
- 超像素:考虑单个像素块会使向量长度过长,且包含的信息过少,所以考虑多个像素块合到一起的超像素块
相当于内部Transformer把每一个patch当作一个图像,重复进行计算
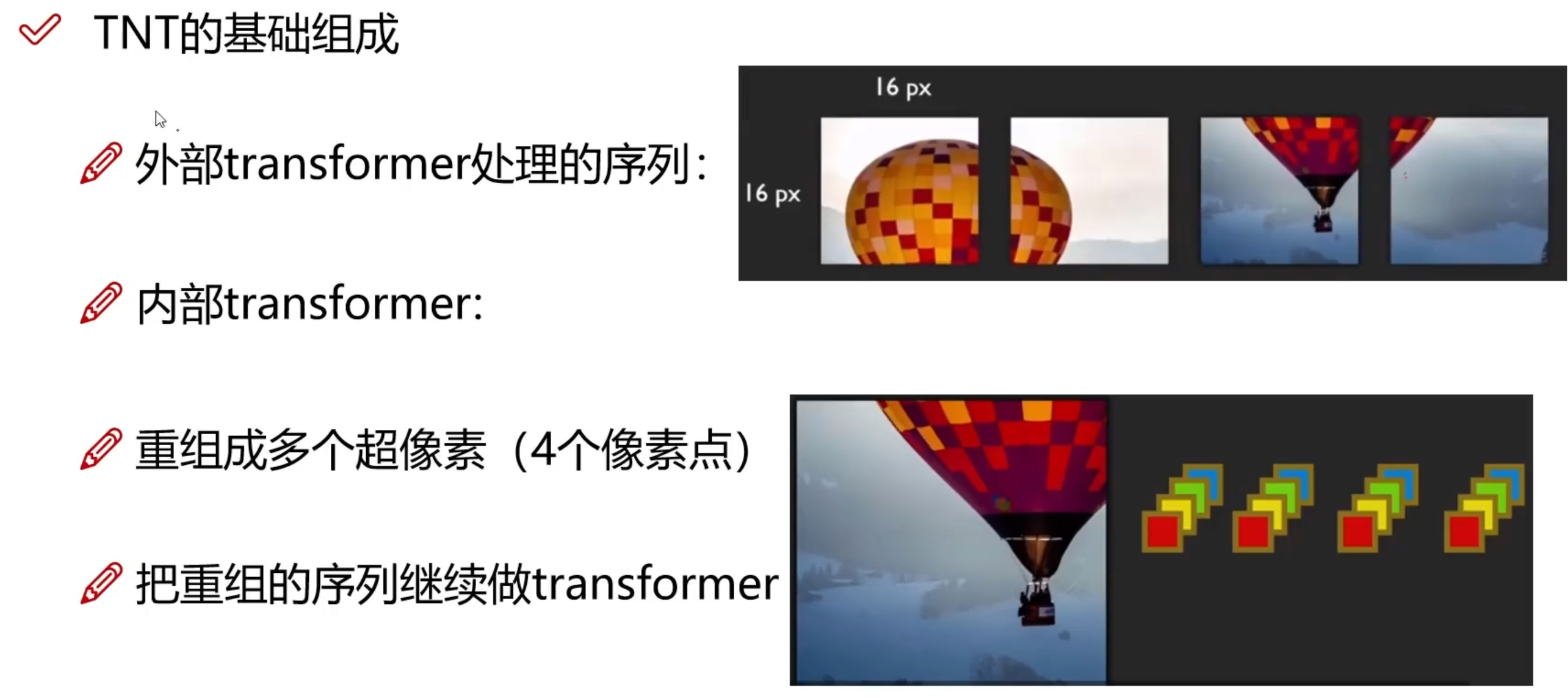
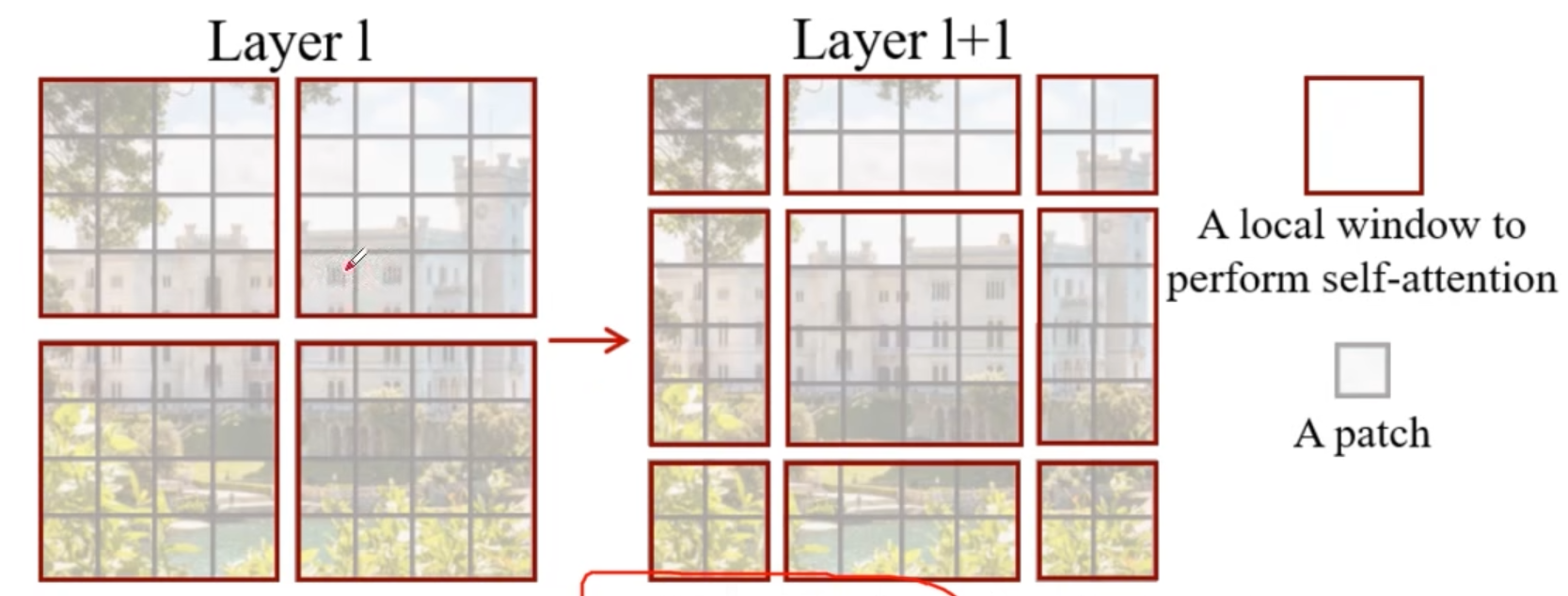
Swing Transformer
整体框架
-
使用了类似卷积神经网络中的层次化构建方法
-
引入了窗口的形式将一个一个的feature map分割开
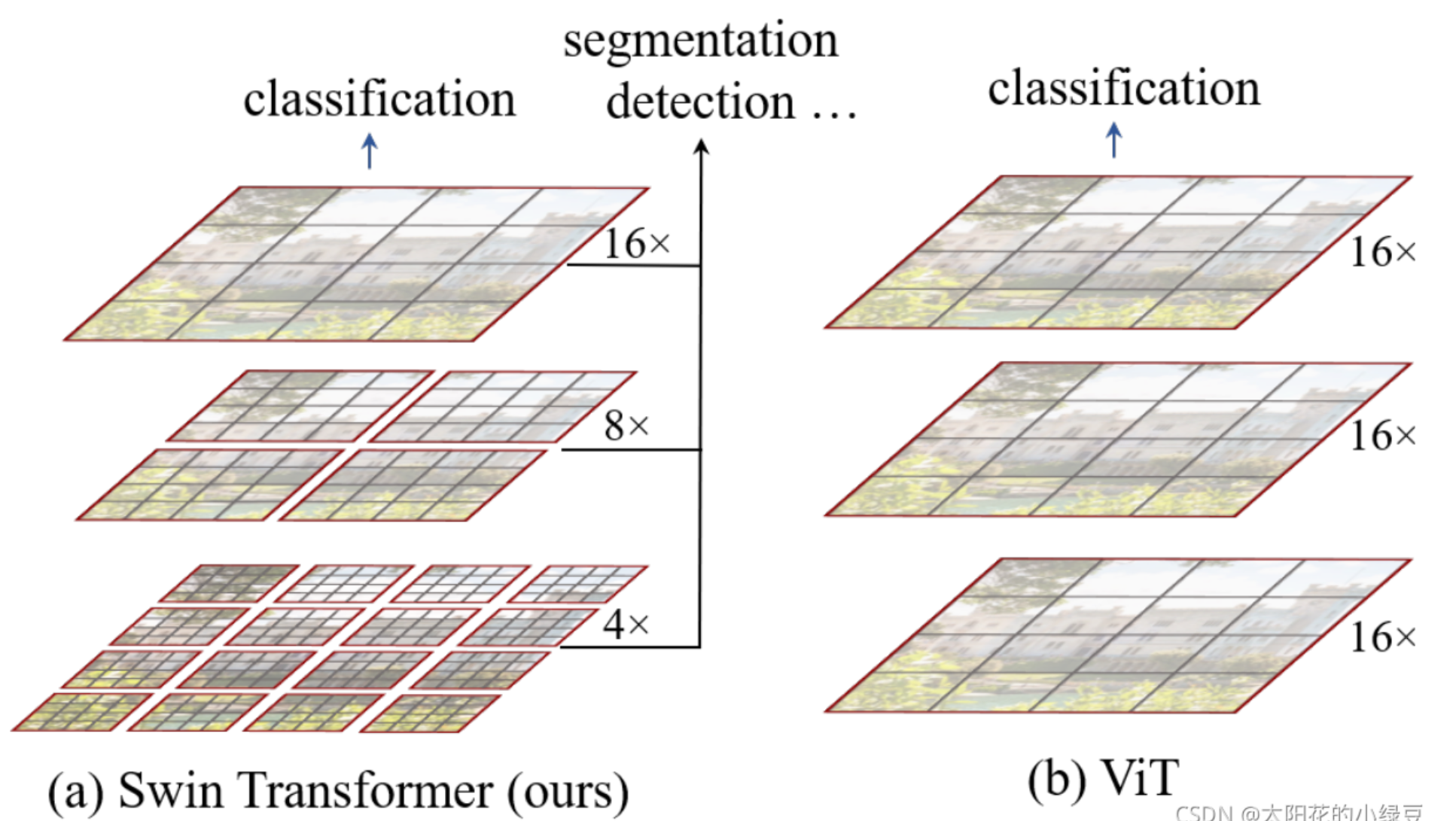
总体框架如下:
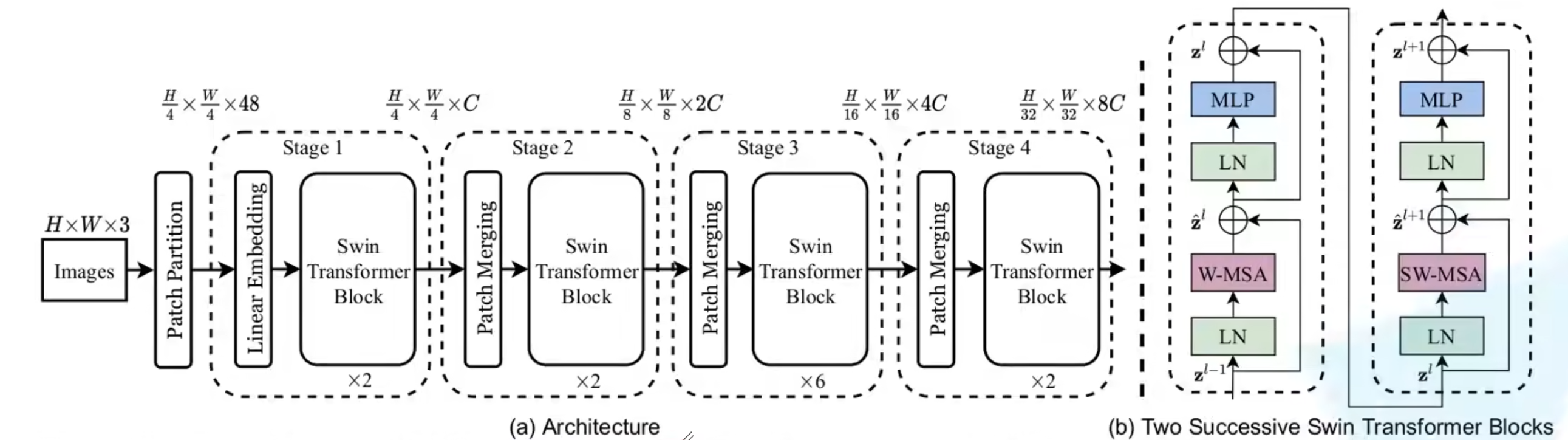
各组件介绍
- Patch Partition和Linear Embedding:等价于对图像先后做了两次卷积
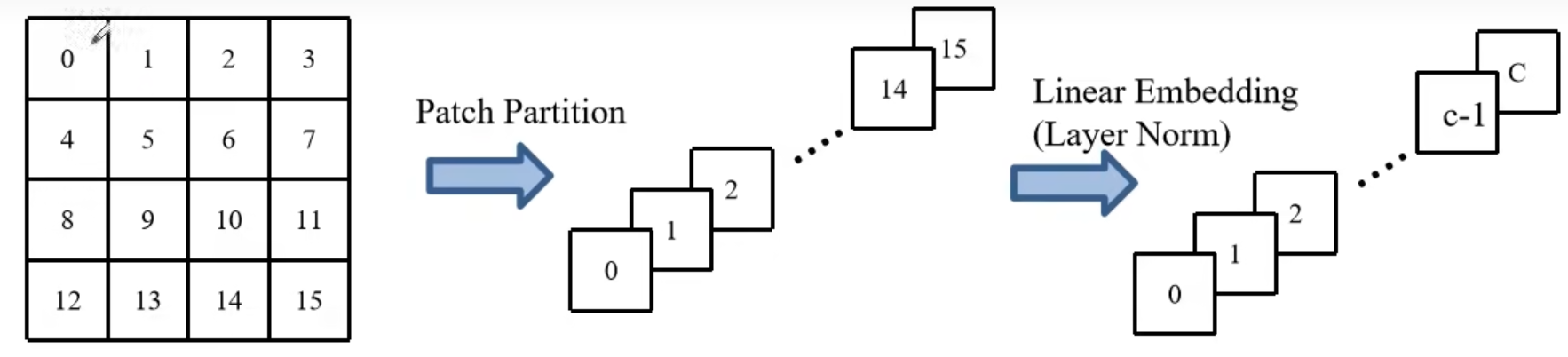
-
Patch Merging:相当于一个下采样(将输入数据的分辨率降低,以降低模型的计算复杂度),但同时增加了深度(类比VGG)
①四个窗口,将每个窗口相同位置的像素取出,得到四个特征矩阵;
②四个矩阵在深度方向进行拼接;
③在深度方向上进行layer normal处理;
④通过全连接层对每一个像素在深度方向进行线性映射
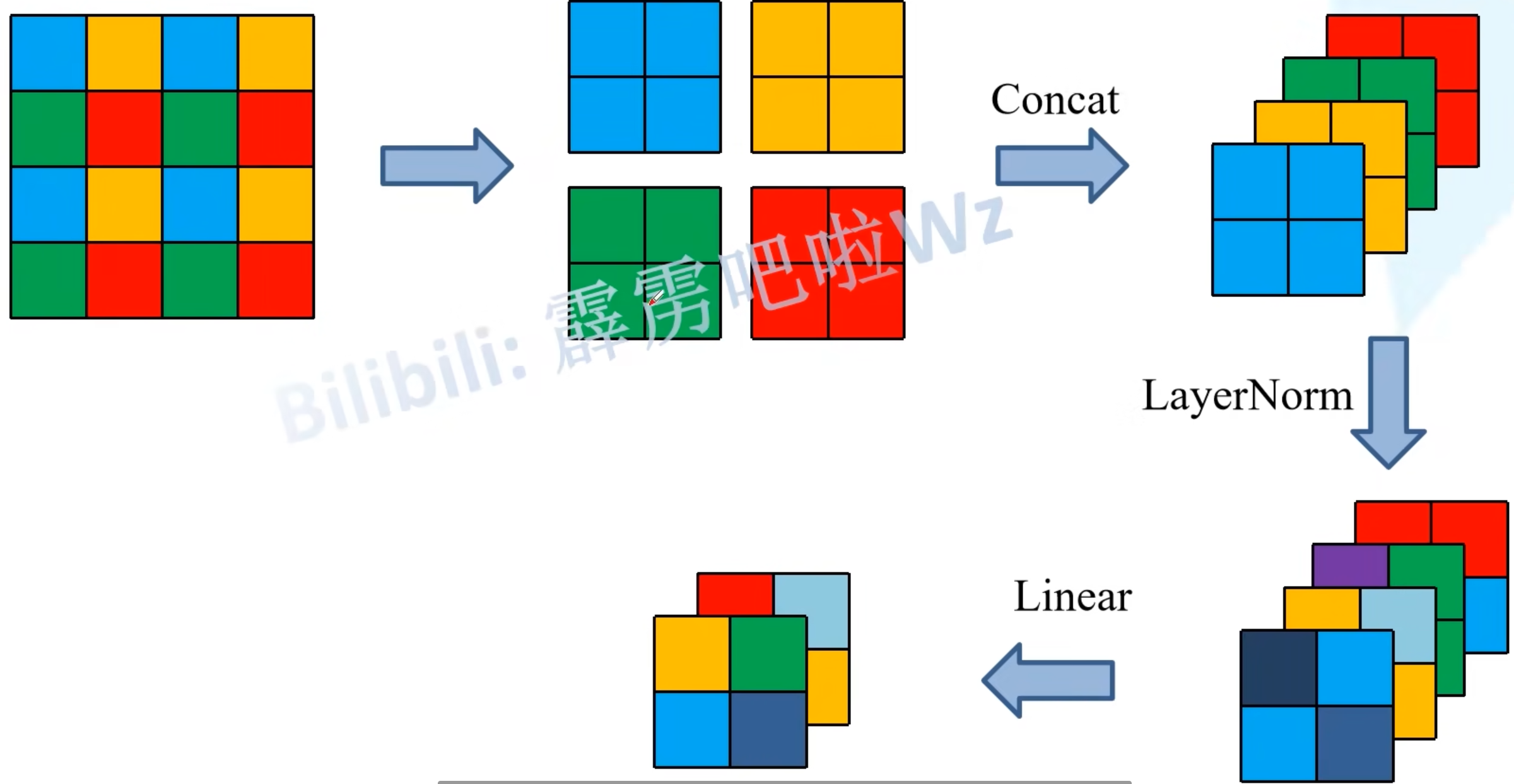
-
W-MSA:基于窗户的自注意力机制
将特征图分成四个window,在每个window内部进行MSA计算,缺点是window之间不能通讯,目的是为了减少计算量
-
SW-MSA:窗口滑动后重新计算自注意力机制
目的是解决窗口之间不能通讯的缺点;现在将窗口向右下移动
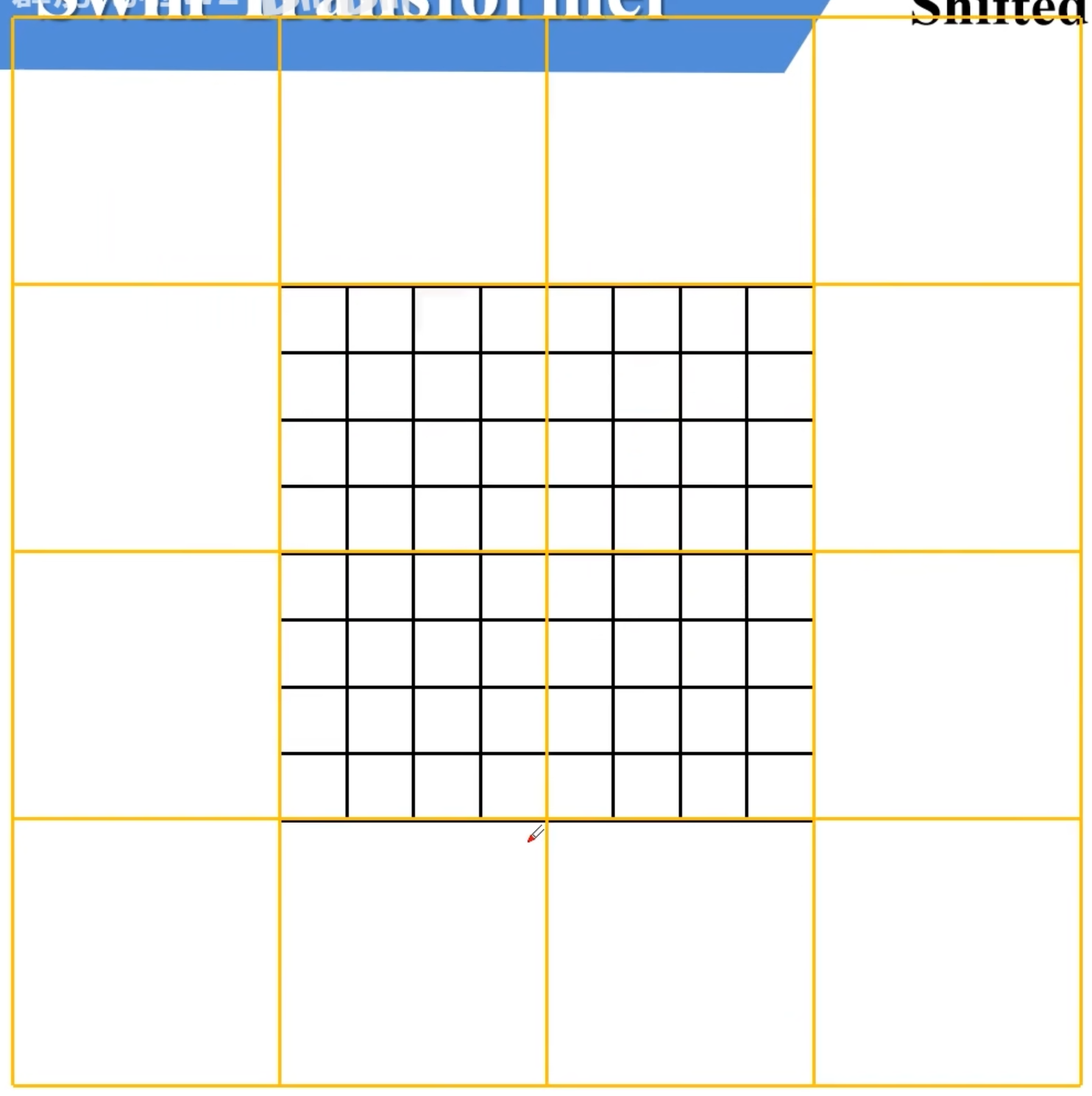
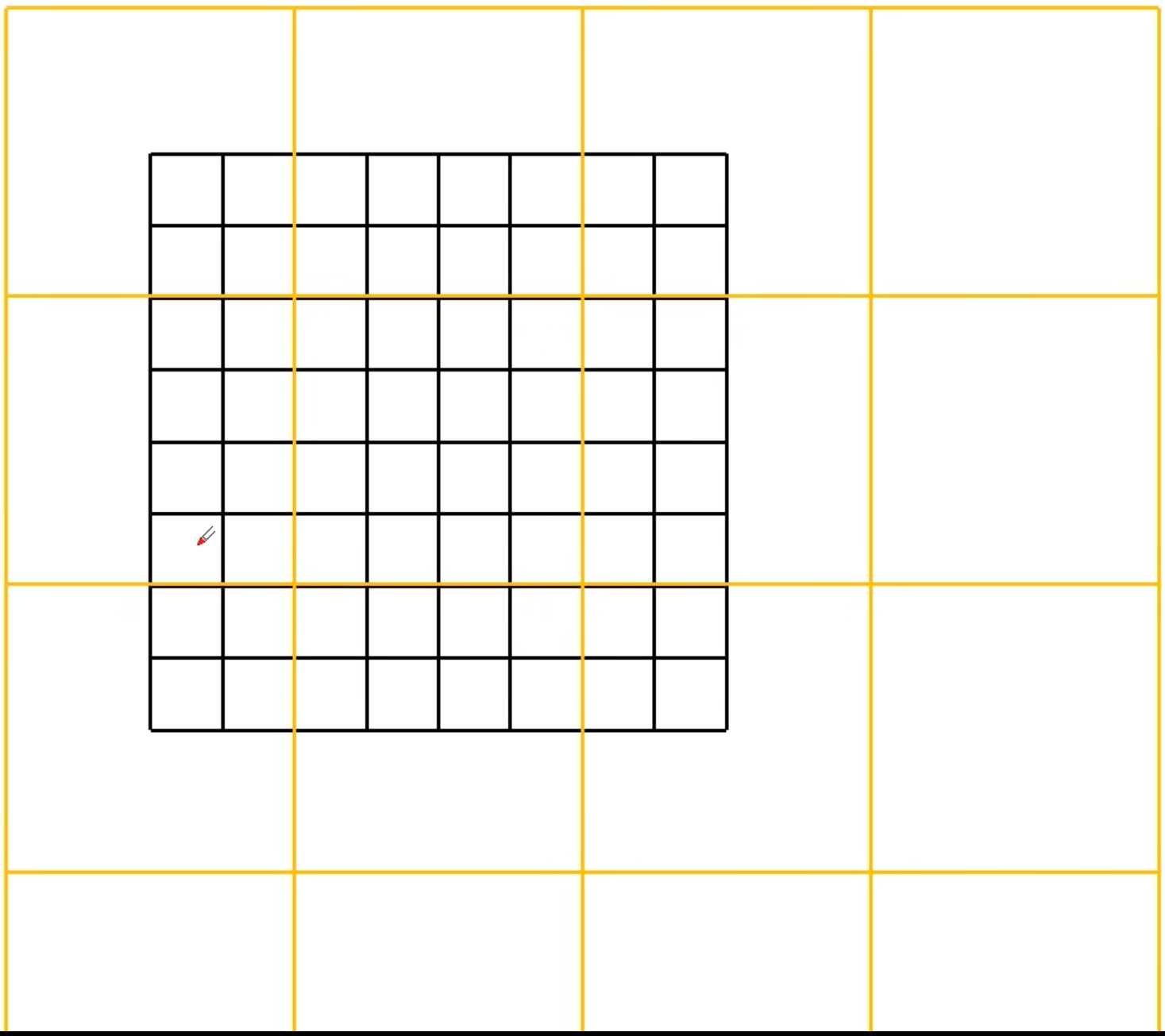
重新划分结果如下:
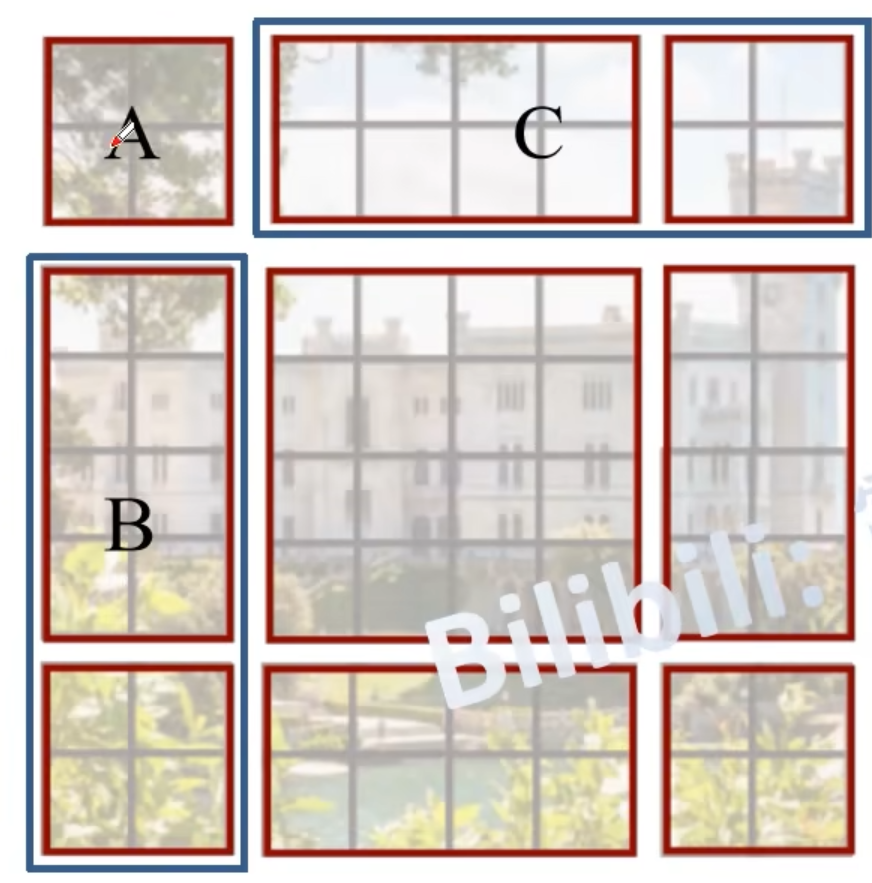
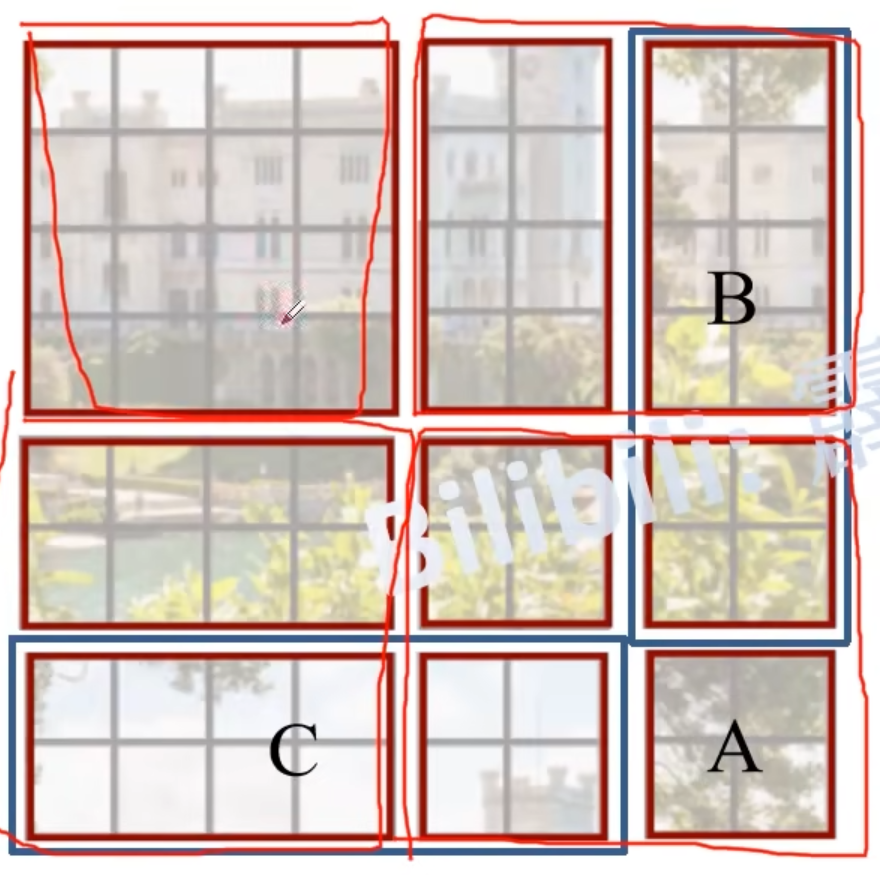
现在得到了九个窗口,那么怎么减少计算量呢?将A和C移到最下面,再将A和B移到最右边,得到右图,又可以看成四个window,但如右下的大window中的每个小wiondow在原始图像中不是连续的,破坏了位置信息,所以要进行一种masked MSA
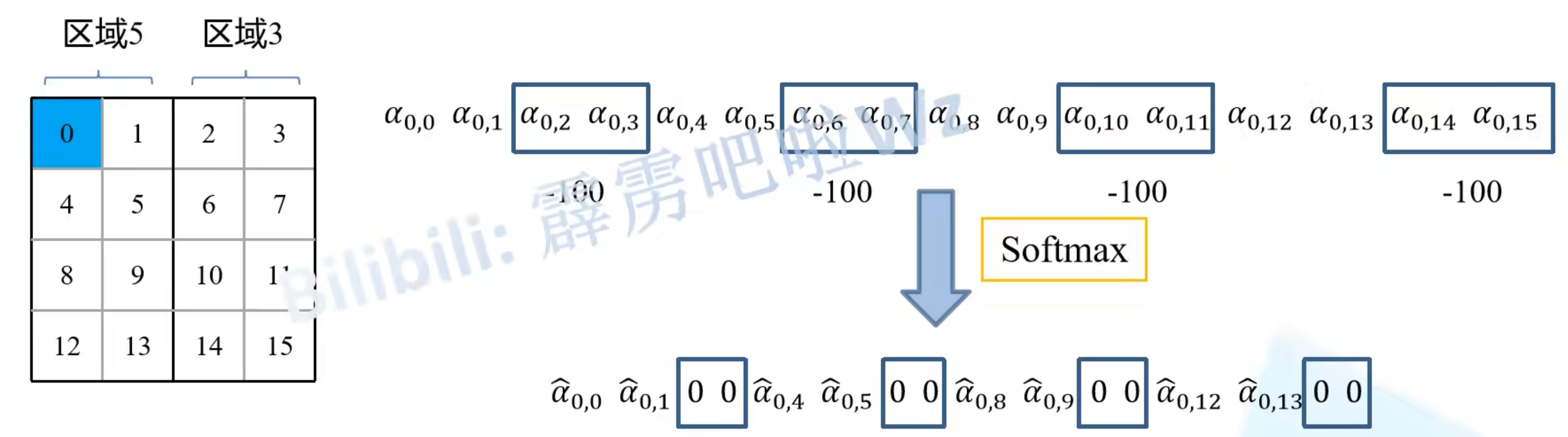
比如在计算区域5时不希望引入区域3的数据,在计算注意力机制时,就将区域3所对应的attention score都减去100,得到绝对值很大的非负数,在进行softmax处理后就等于0了,最后将数据移回原来的位置即可
-
Relative position bias:在计算attention时要加上相对位置偏置
相对位置索引 $=$ 基准点的绝对位置索引 $-$ 比较点的绝对位置索引,将得到的四个矩阵按行展开,合并成一个矩阵
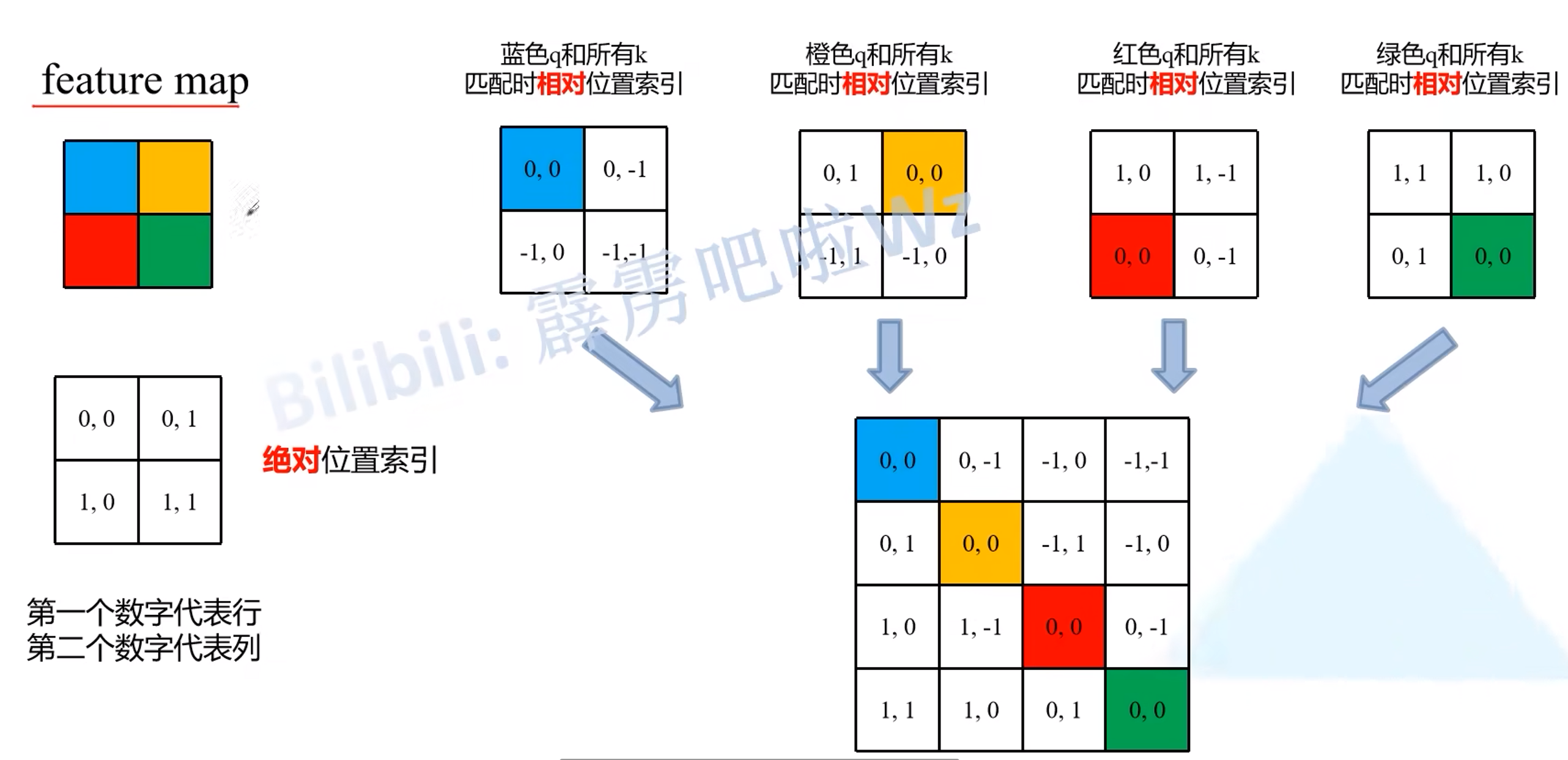
将二元坐标转换成一元坐标,①行、列加上$M-1$,其中$M$是窗口大小,对应这里的$M$就是2;②行标乘上$2M-1$;
根据得到的一元索引在relative position bias table中取到对应的relative position bias


-
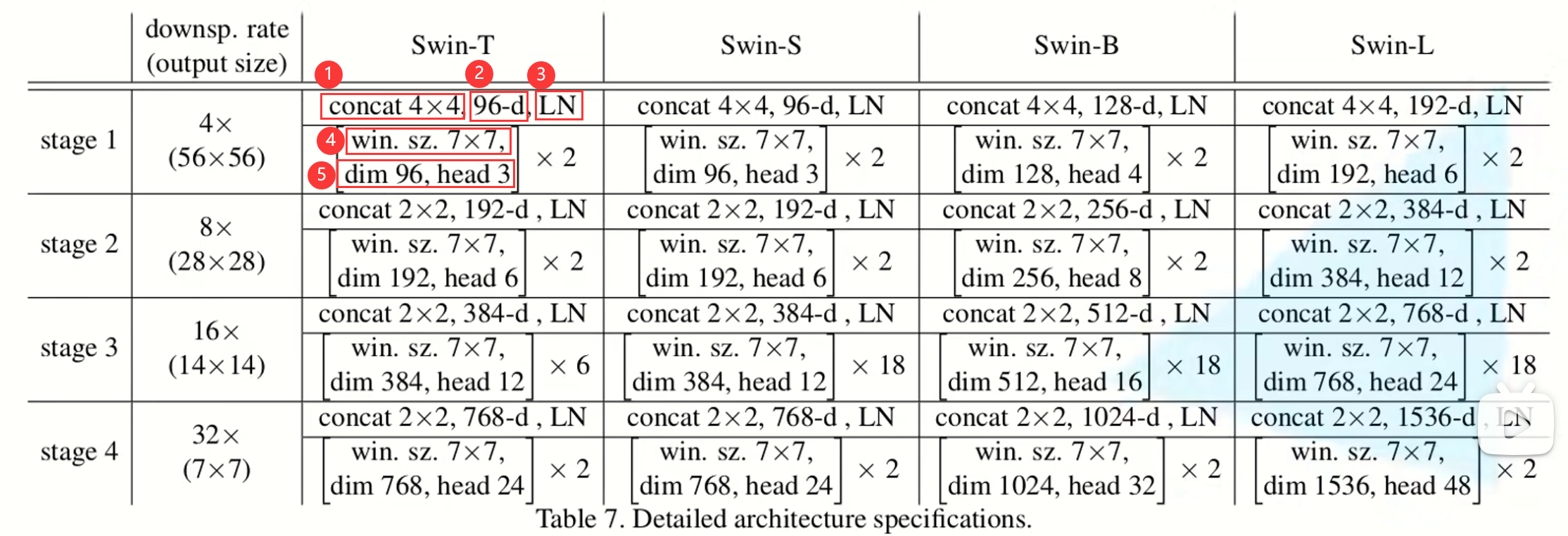
详细参数:①下采样的比率;②深度;③Layer Normalization;④window size;⑤dimension即深度,head即多头的数量
有Tiny、Small、Base、Large四种模型
本着互联网开源的性质,欢迎分享这篇文章,以帮助到更多的人,谢谢!