自注意力机制概述
-
自注意力机制解决深度学习模型的输入是一组向量且大小不等的问题,如nlp(word embedding),语音处理,图(Graph)
关于输出可以分为三类:
-
n个输入,n个输出:词性标注、社交网络中的用户分析等
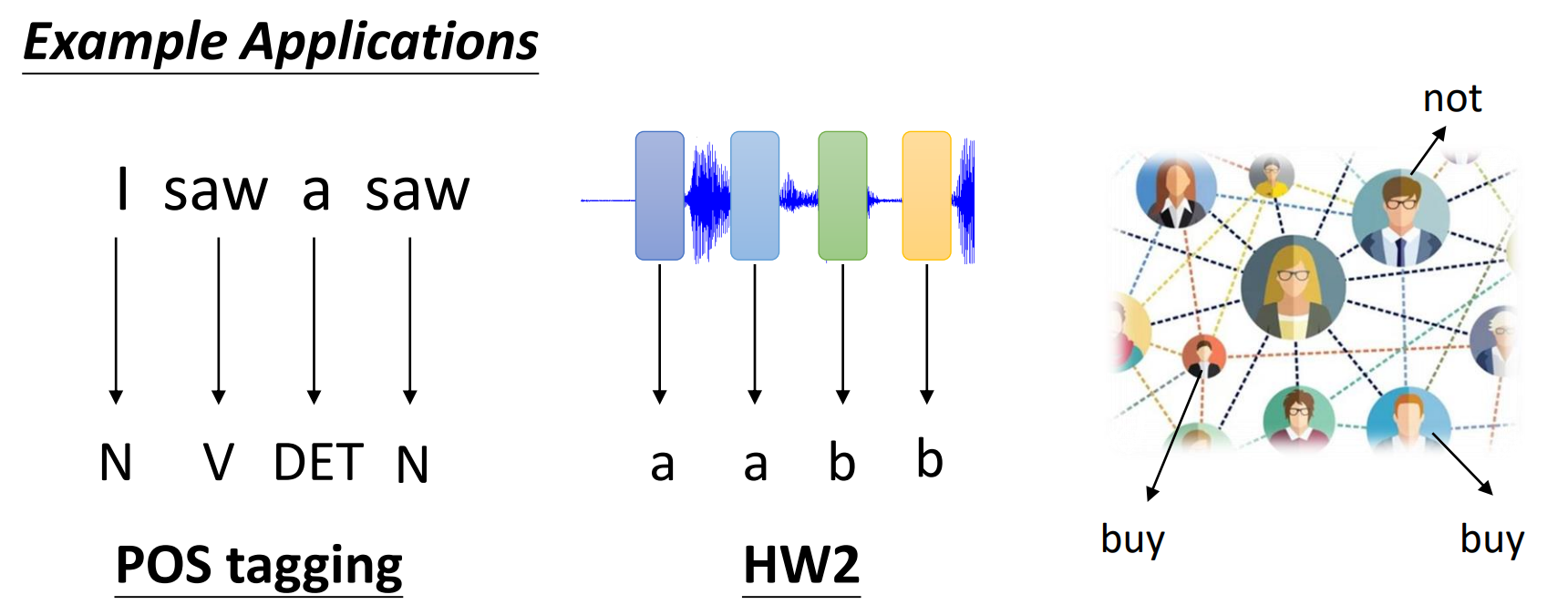
-
n个输入,1个输出:情感分析,语音识别谁的声音
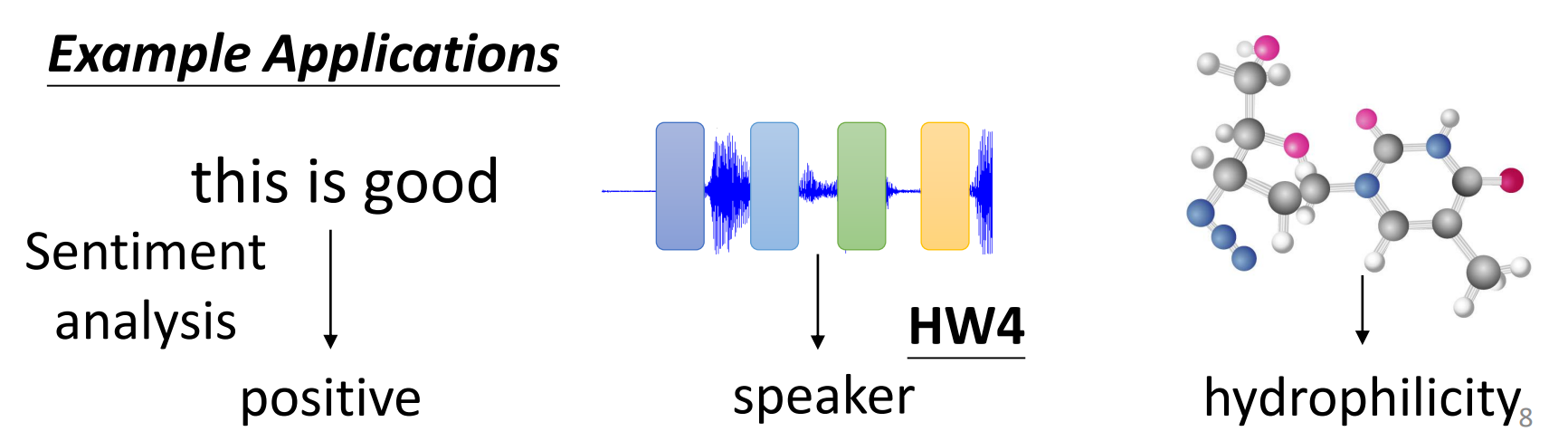
-
n个输入,m个输出:即seq2seq,如语言识别出文字
-
-
一个词性标注的例子:I saw a saw,如果简单地使用全连接层输出结果,两个saw的结果会一样,因为没有考虑上下文(传统的word2vector也有这一问题),并且输入是定长的,而自注意力机制可以解决这个问题:将四个向量组成的sequence全交给self-attention,self-attention会考虑整个sequence后输出结果,当然self-attention可以层级使用
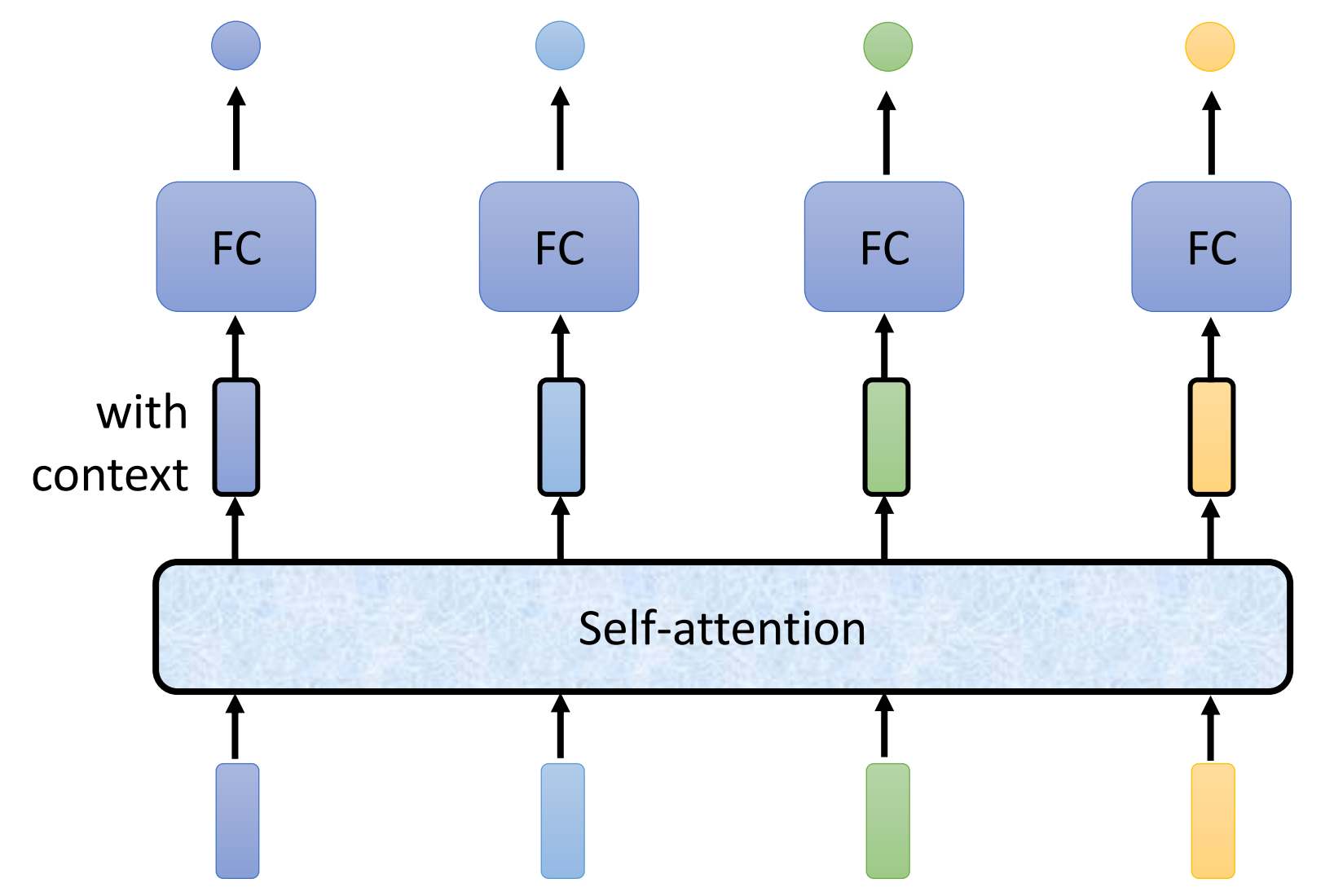
-
从整个sequence中找出哪些部分是重要的,哪些决定$a^{1}$的class/regression,每一个向量与$a^{1}$的关联程度用$α$(attention score)表示
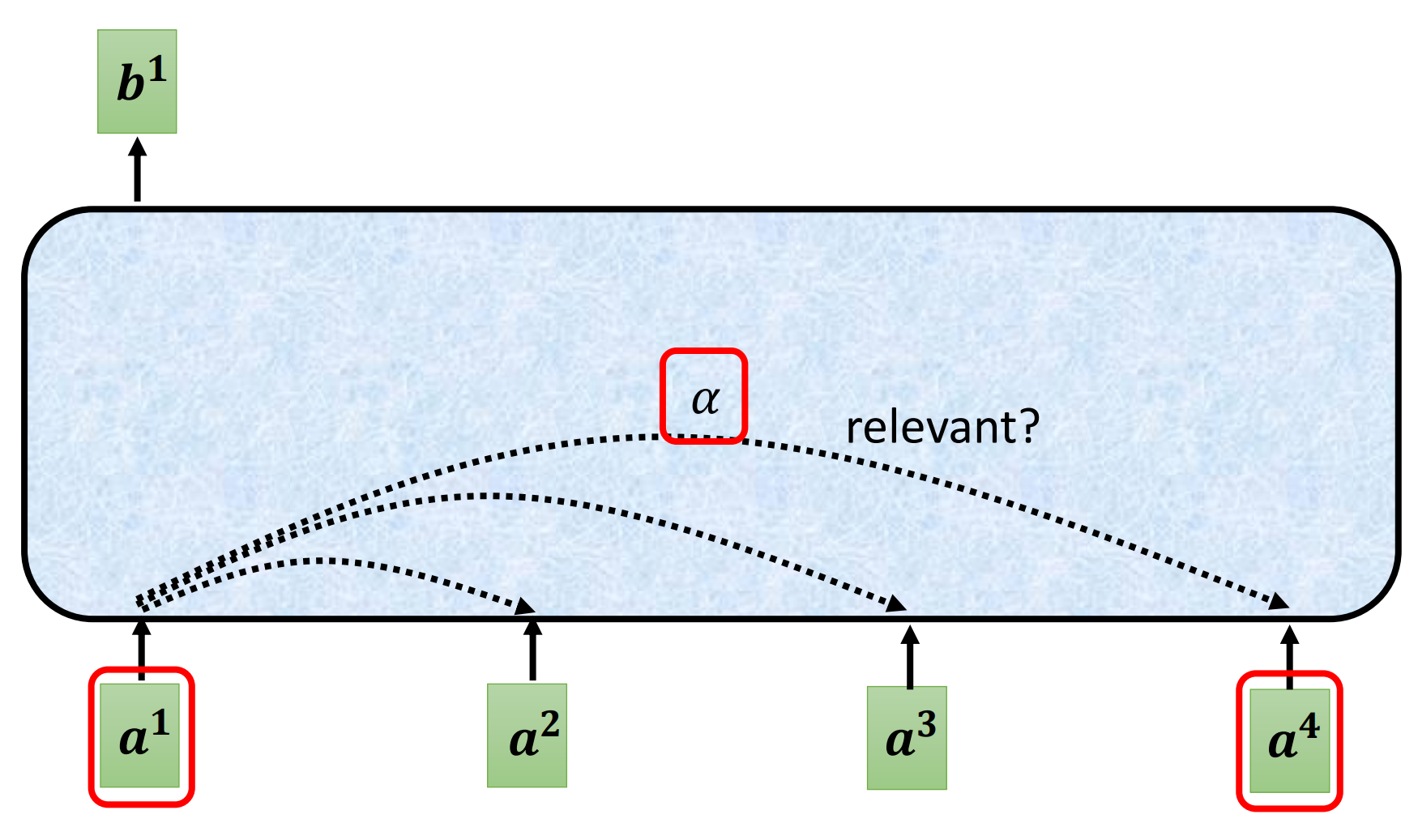
那么怎么计算$α$的大小呢?
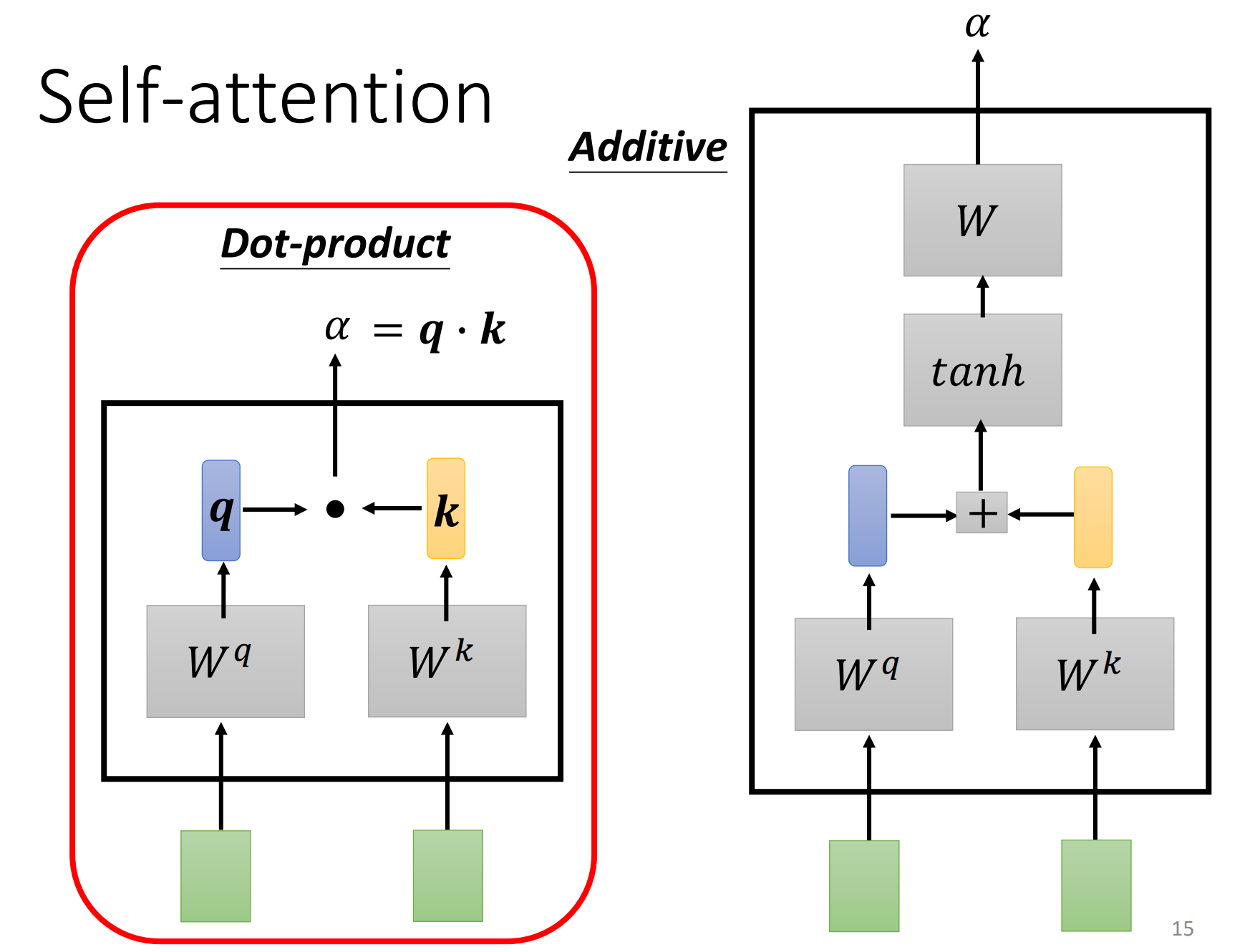
通常有Dot-product和Additive两种方法,Dot-product最常用
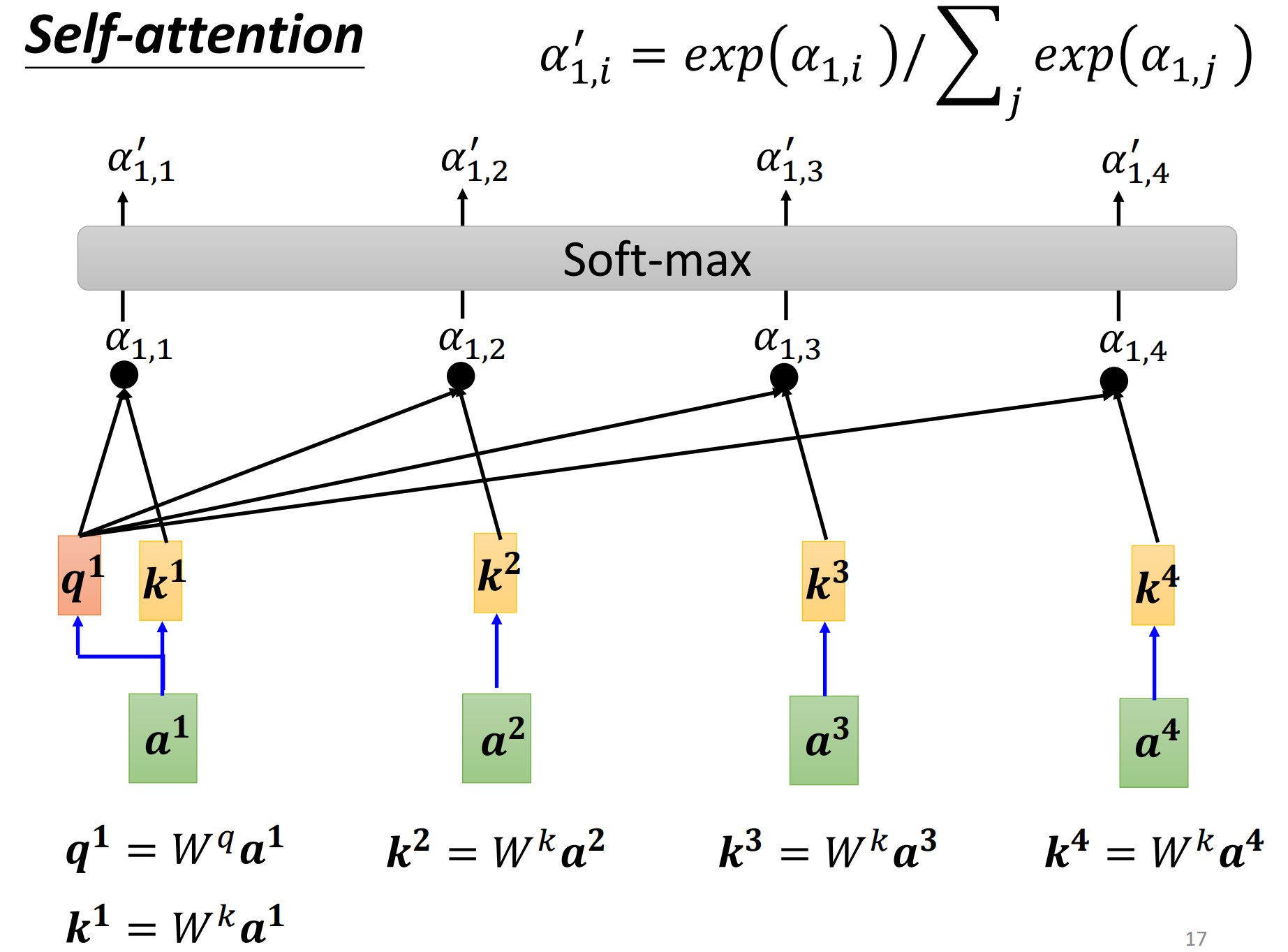
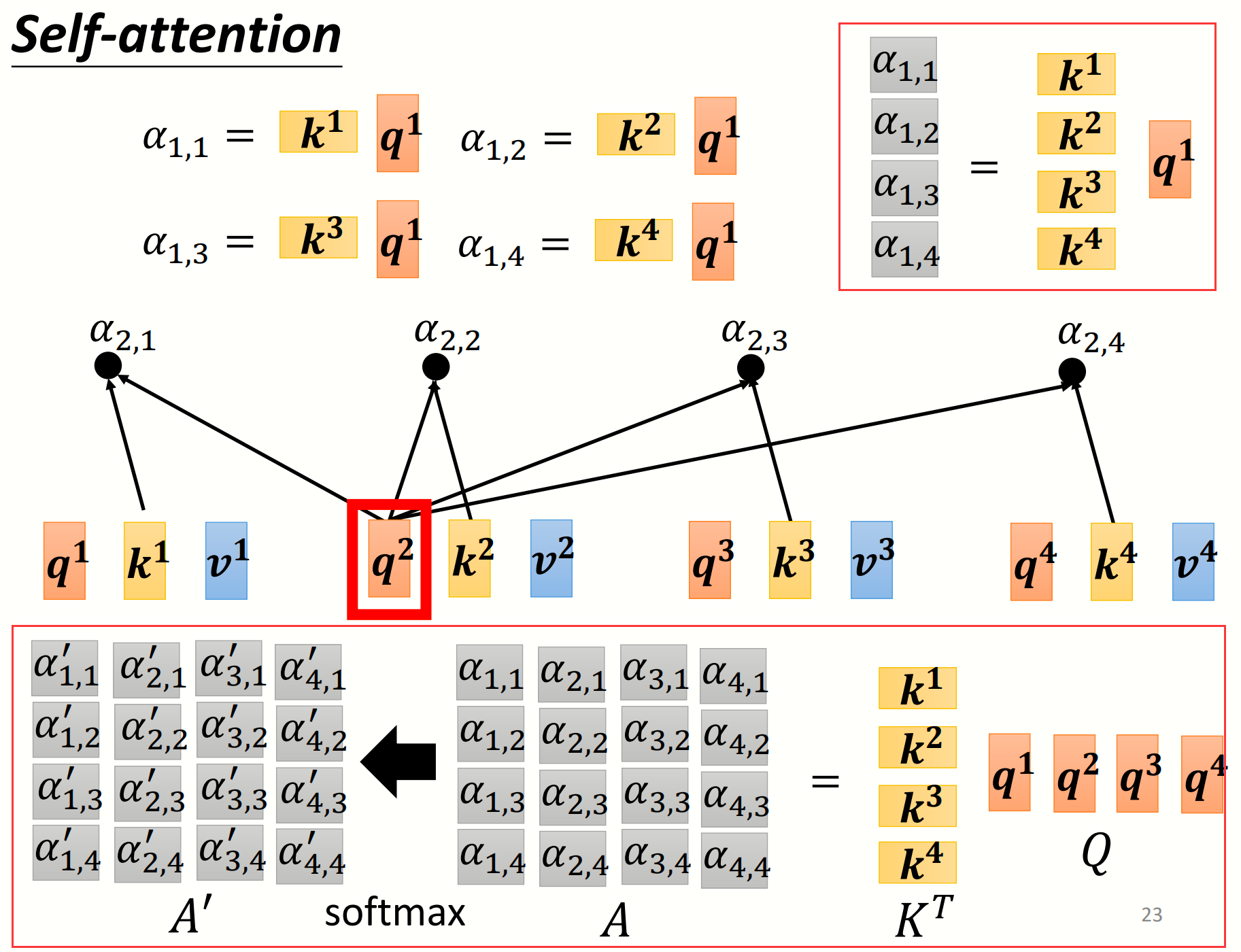
现在要计算$a^{1}$的输出结果,先计算出$a^{1}$的$q$(query),再计算剩余三个向量的$k$(key),通过dot-product计算出attention-score,注意要对向量长度做一个归一化(除以$\sqrt{d_{k}}$,因为当长度很长时,去做softmax会使差距变大),最后通过softmax函数做一个normalization,也可以选择ReLu等激活函数
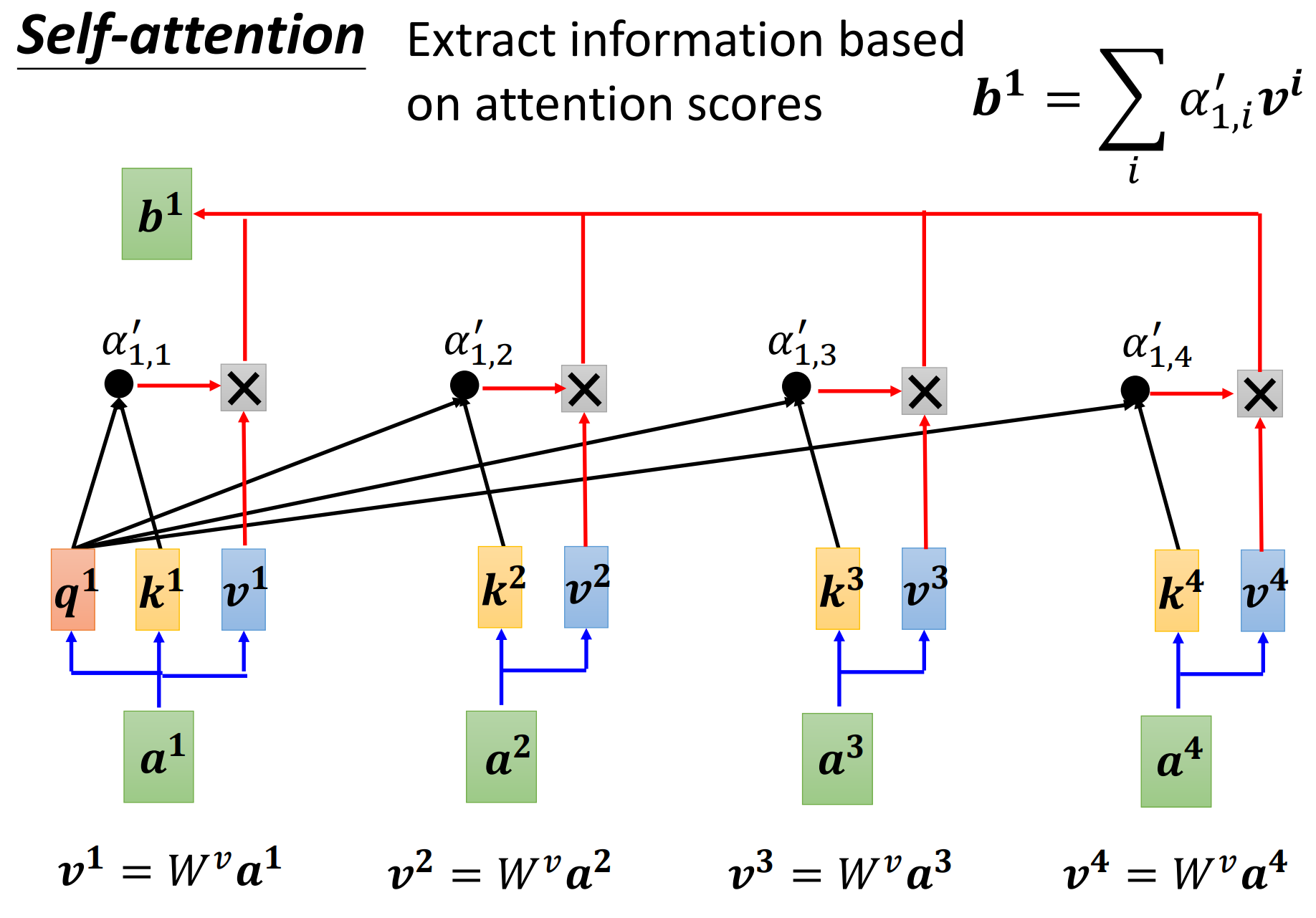
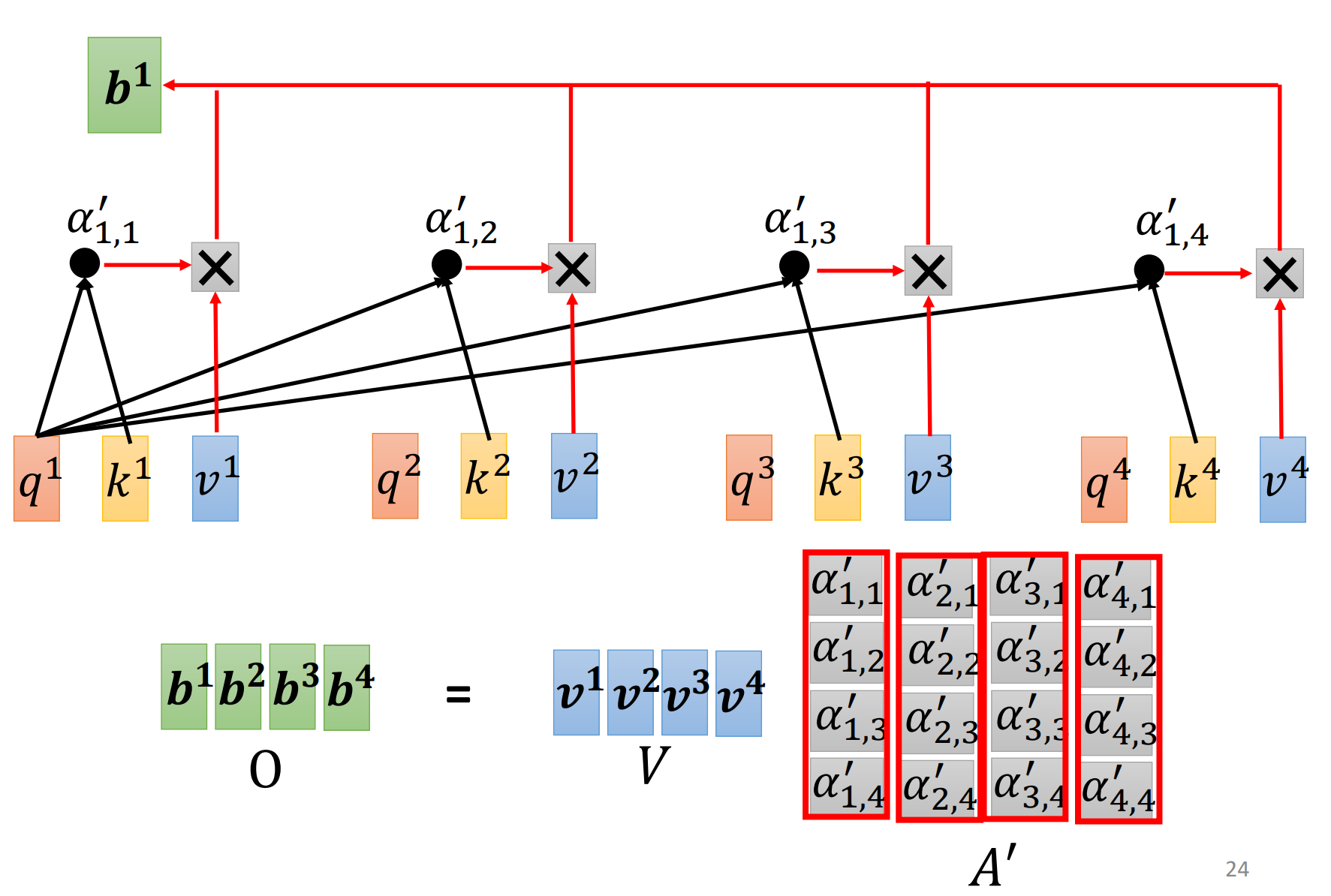
分别乘以$W^{v}$,得到向量$v$(value)后与$α$相乘,最后全部相加即得输出结果$b^{1}$
矩阵角度——自注意力机制
通过转换成矩阵计算,相当于实现了并行加速
-
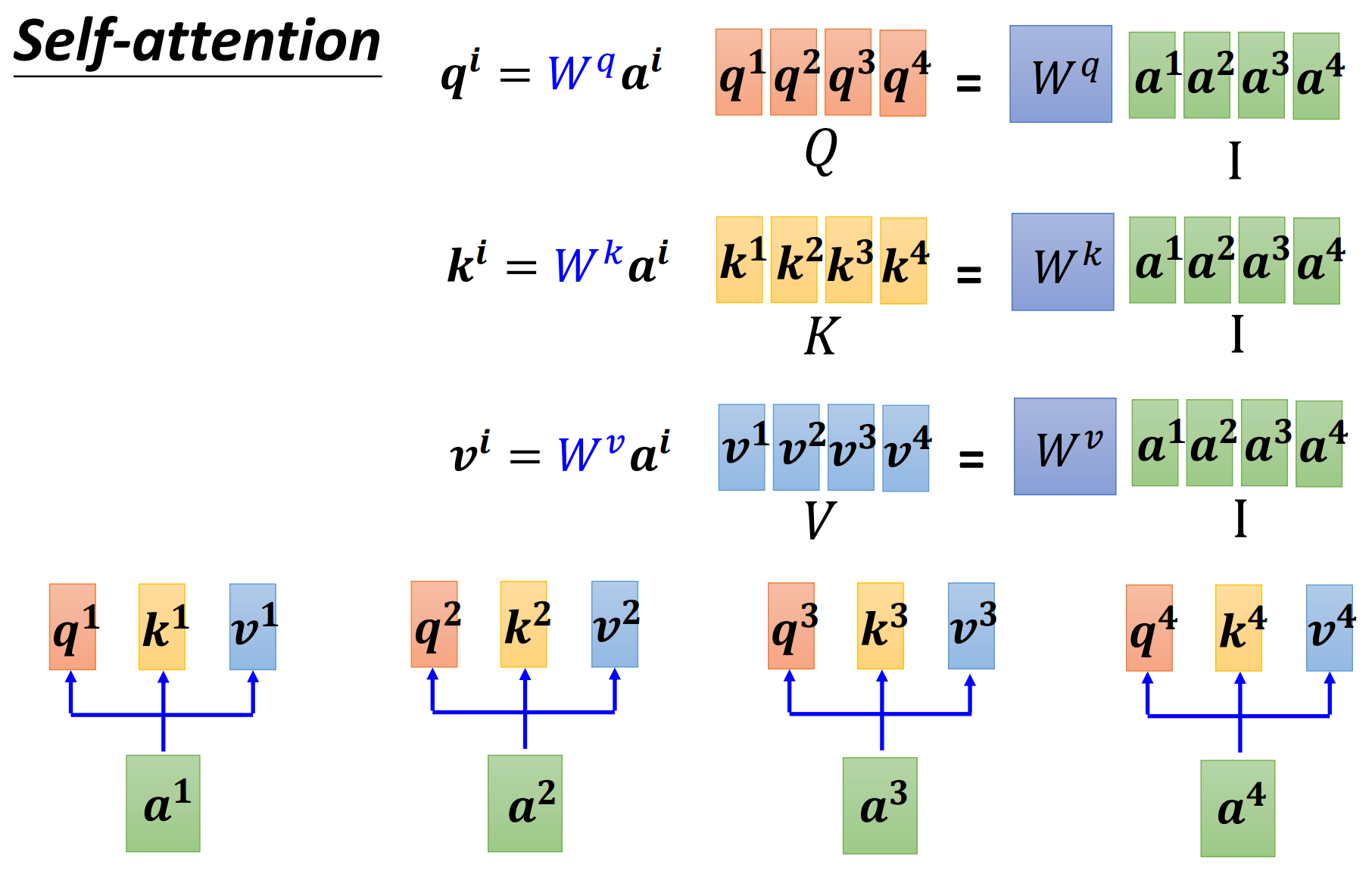
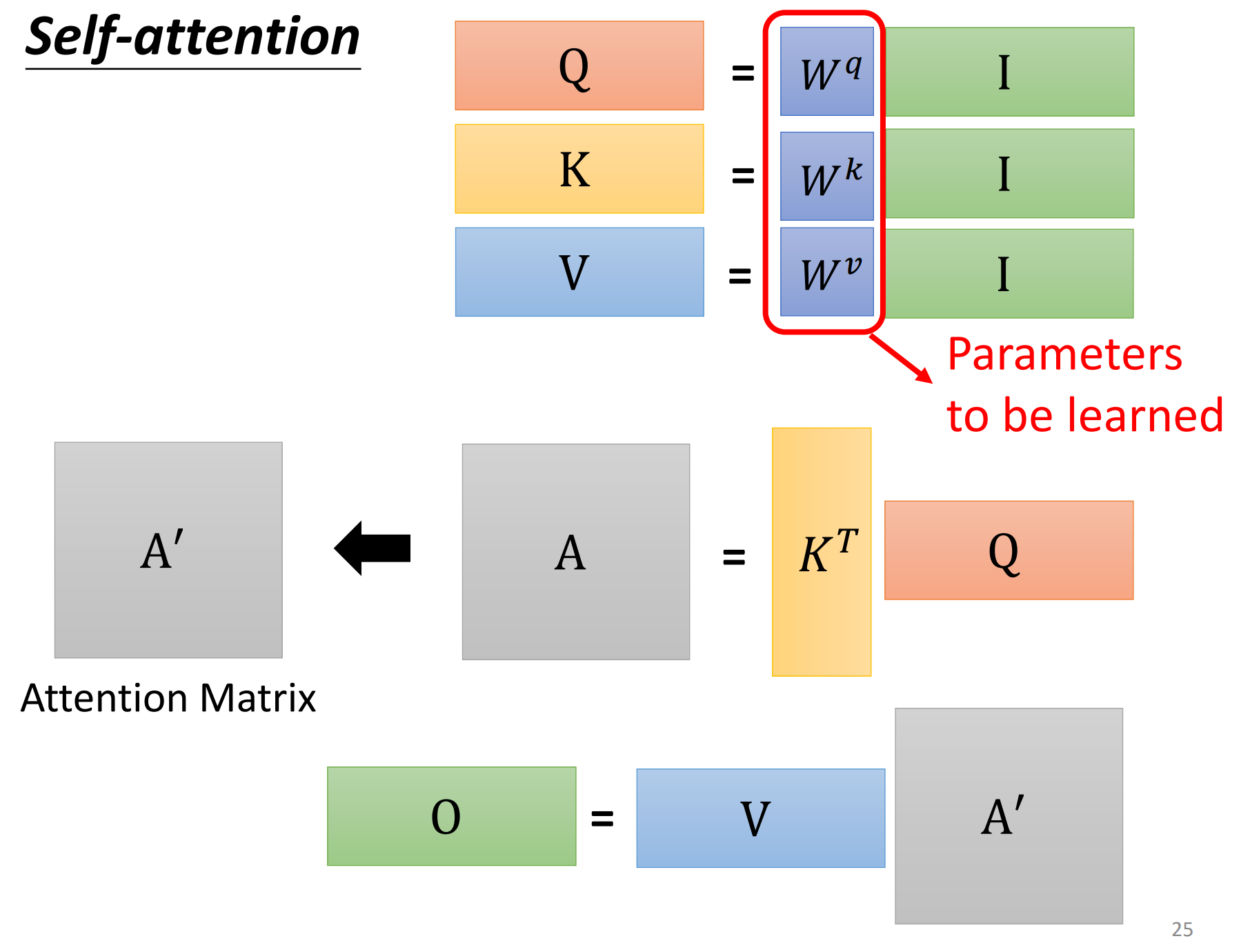
Step1: $W^{q}$、$W^{k}$和$W^{v}$相当于network的参数,可以把四个向量合成一个矩阵去理解,即相当于矩阵变换
-
Step2: 计算$\alpha$相当于做了一个矩阵和向量的乘法,再把向量$q$排成一个矩阵,就得到了最终所有的$\alpha$
-
Step3: 同理,output的计算也可以从矩阵的角度理解
-
最后整个的计算过程如下:
Multi-head Self-attention
-
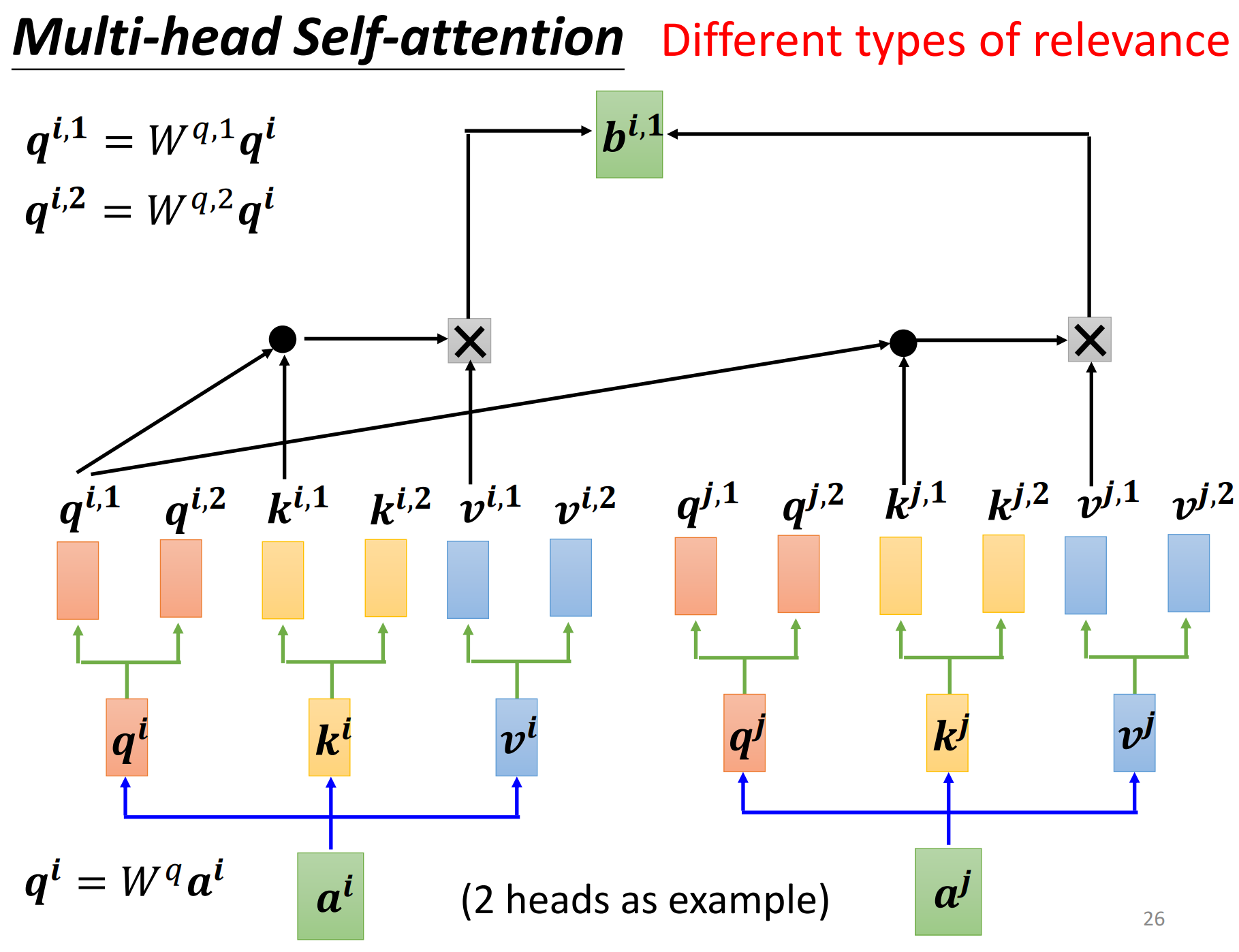
single head self-attention可以理解为学习input之间的相关性,但input之间的相关性可能不止一种,所以就有了multi-head,每一种相关性,就表示一个head,学习到不同意义的特征,head的具体数目是一个hyper parameter
-
将$q^{i}$乘以另外两个矩阵,得到$q^{i,1}$和$q^{i,2}$,相应的$k$和$v$都有两个,做self-attention时,1那一类的一起做,2那一类的一起做,
-
将$b^{i,1}$和$b^{i,2}$拼接起来,再通过一个矩阵变换(通常是一个全连接层,综合所有特征后输出结果,用于降维)得到最终的$b^{i}$,送到下一层去
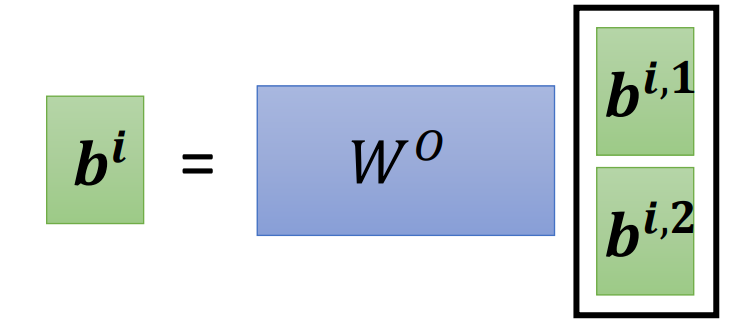
Positional Encoding
-
使用self-attention的layer丢失了位置的信息(如在词性标注中很重要),虽然在前面学习中标注了1234,但实际处理中没有先后次序,“天涯若比邻”
-
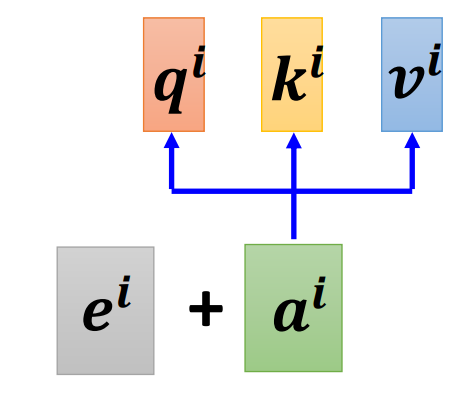
为每一个位置设定一个vector $e^{i}$,叫做positional vector,$i$代表的是位置,这个$e^{i}$可以是人设的(hand-crafted),也可以是learn出来的,尚在研究(截止2021)
在其他领域的应用
-
语音处理:语音处理中的向量大小及数量比NLP要大很多,为了简化运算量,提出了Truncated Self-attention,只关注一个小范围
-
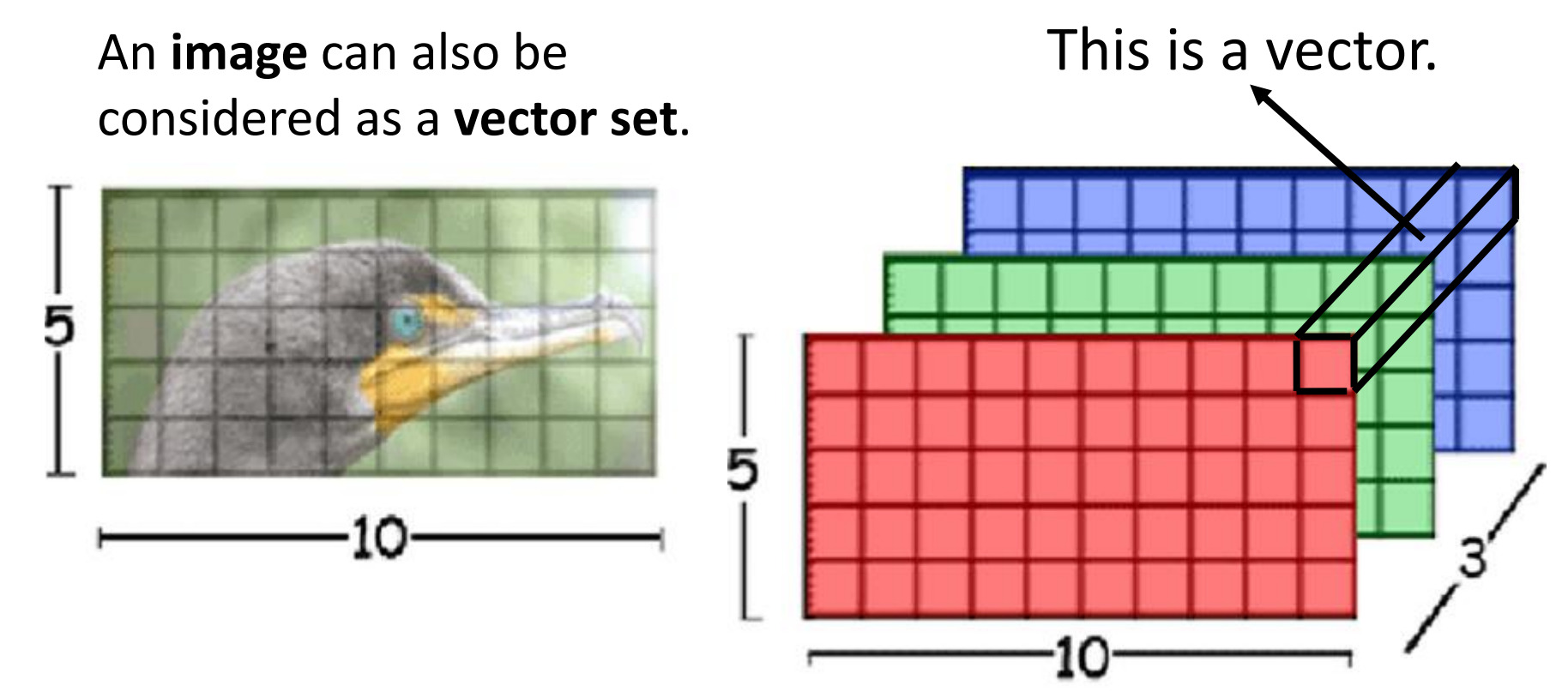
图像处理:将一张图片看成是一个vector set
-
Self-attention v.s. CNN
- CNN的感受野由卷积核的大小决定,只能提取一小部分的特征,难以处理比较长的sequence;而Self-attention关注的是整张图像的信息,所提取特征的位置和数量由自己训练所决定(attention score),不需要人工干预,所以Self-attention包含CNN
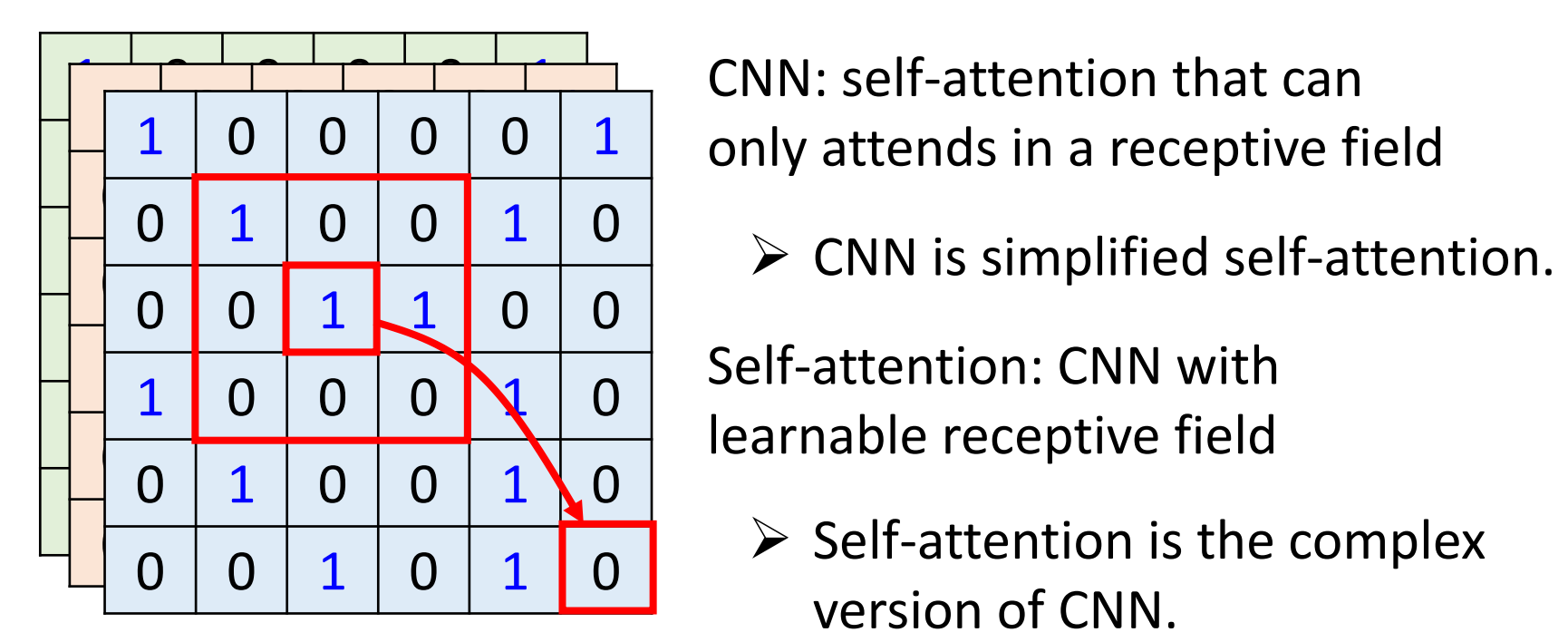
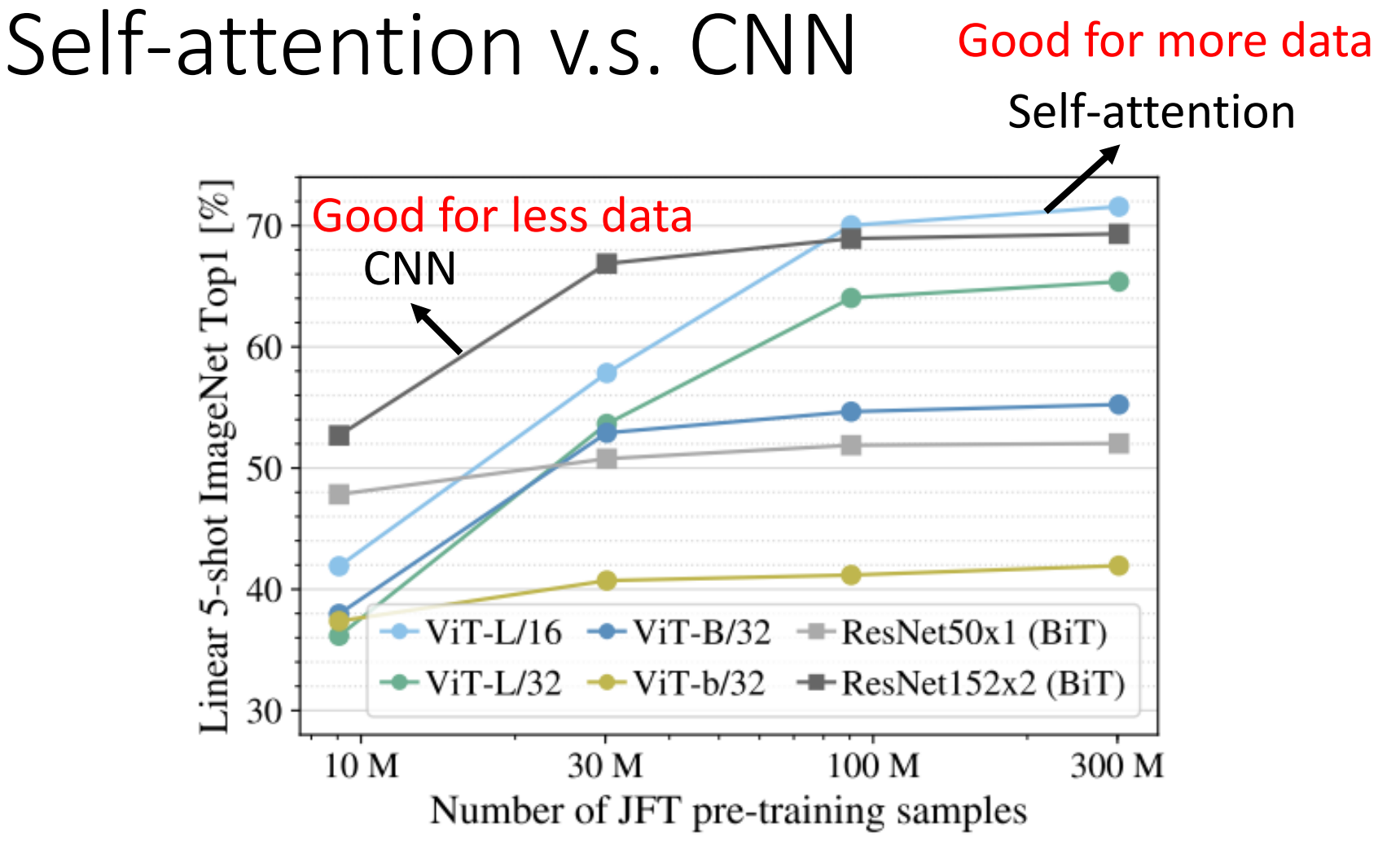
- CNN的限制更多,更适合小数据集,而Self-attention限制更少,更适合大数据集
- 其实Self-attention的多头注意力机制就是为了实现CNN的多通道输出机制
- CNN的感受野由卷积核的大小决定,只能提取一小部分的特征,难以处理比较长的sequence;而Self-attention关注的是整张图像的信息,所提取特征的位置和数量由自己训练所决定(attention score),不需要人工干预,所以Self-attention包含CNN
-
Self-attention v.s. RNN
-
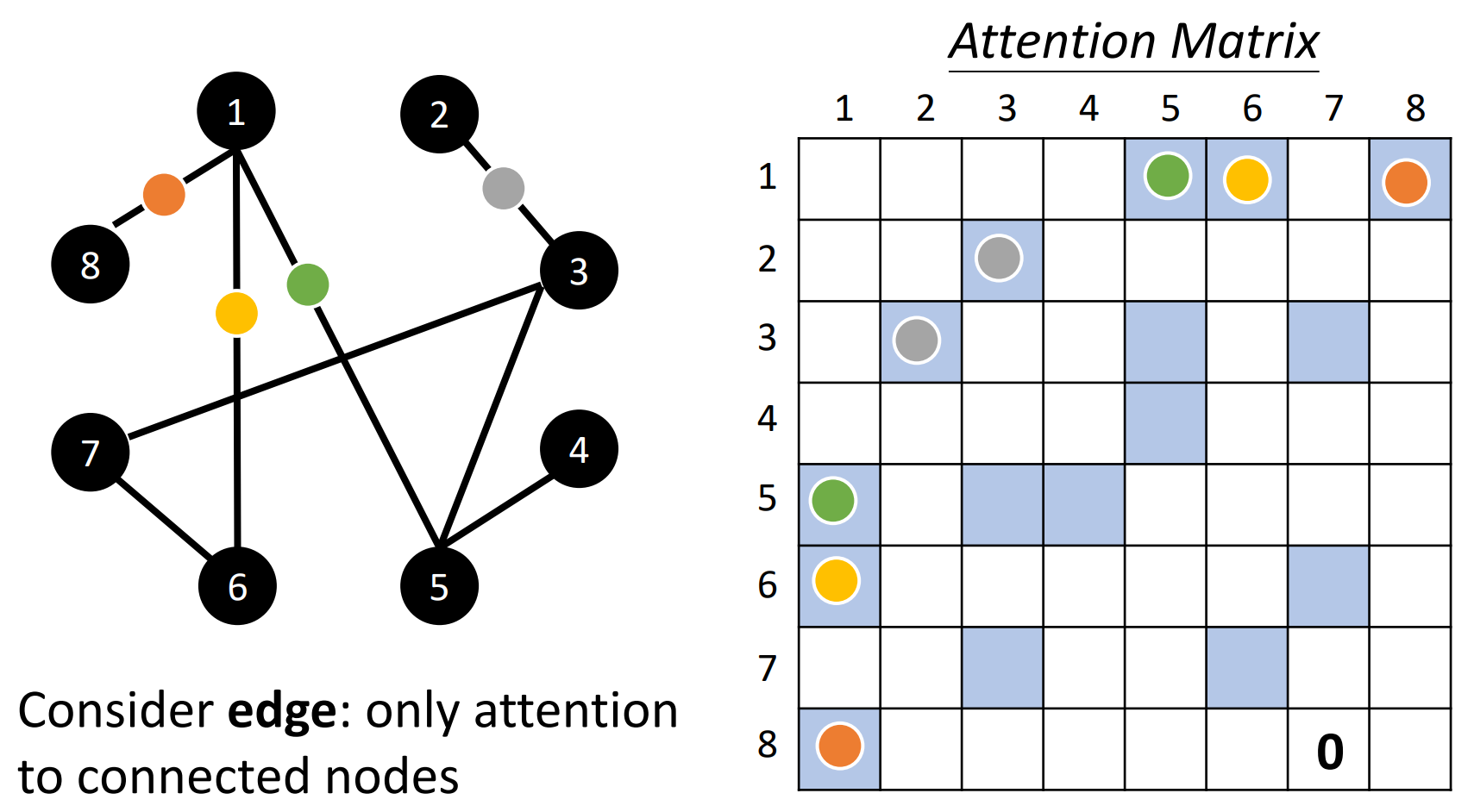
Self-attention for Graph
- 在Graph中,点之间的相关性信息已经由Graph给出,只需要计算有edge相连的node就可以了,不想连的两个node将他们的attention score设为零即可
本着互联网开源的性质,欢迎分享这篇文章,以帮助到更多的人,谢谢!